1. 常见问题解答
1.1. 为什么存在 DepthAI?
在尝试解决嵌入式 Spatial AI 问题(此处 有详细信息)时, 我们发现尽管存在完美的芯片,但没有平台(硬件,固件或软件)可以使用该芯片来解决此类嵌入式空间 AI 问题。
因此,我们构建了这个平台。
1.2. 什么是 DepthAI?
DepthAI 是嵌入式、高性能、空间AI+CV平台, 由开源硬件,固件,软件生态系统组成, 提供完整并可立即使用的嵌入式 Spatial AI+CV 和硬件加速的计算机视觉。
它为嵌入式系统提供了实时的类似于人的感知能力:物体是什么以及它在物理空间中的位置。
它可以与现成的 AI 模型一起使用( 此处 为操作方法),也可以与自定义模型(使用我们提供的训练流程训练的)一起使用(此处 为操作方法)。
下面是一个自定义训练模型的示例,其中机器人使用 DepthAI 通过成熟度自动选择草莓并对其进行分类。
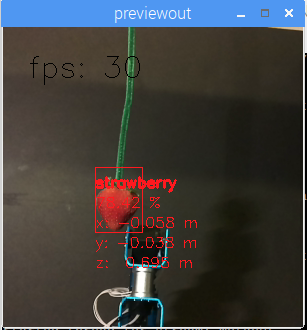
学生可以在周末通过使用免费的在线训练资源, 来训练自己的模型。
DepthAI 也是开源的(包括硬件)。 这样做是为了使公司(甚至个人)可以快速,自主且低风险地对解决方案进行原型设计和生产。
请参阅 下面 我们的(MIT-Licensed) GitHub 的摘要,其中包括开源硬件,固件,软件和机器学习训练。
1.3. 什么是 SpatialAI? 什么是 3D 目标定位?
首先,有必要定义 “对象检测” 是什么:

它是用于在图像的像素空间(即像素坐标)中找到感兴趣对象的边界框的技术术语。
3D 目标定位(或 3D 目标检测)就是在物理空间而不是像素空间中找到此类目标。 在尝试实时测量或与物理世界互动时,这很有用。
以下是展示目标检测和 3D 目标定位之间区别的可视化效果:
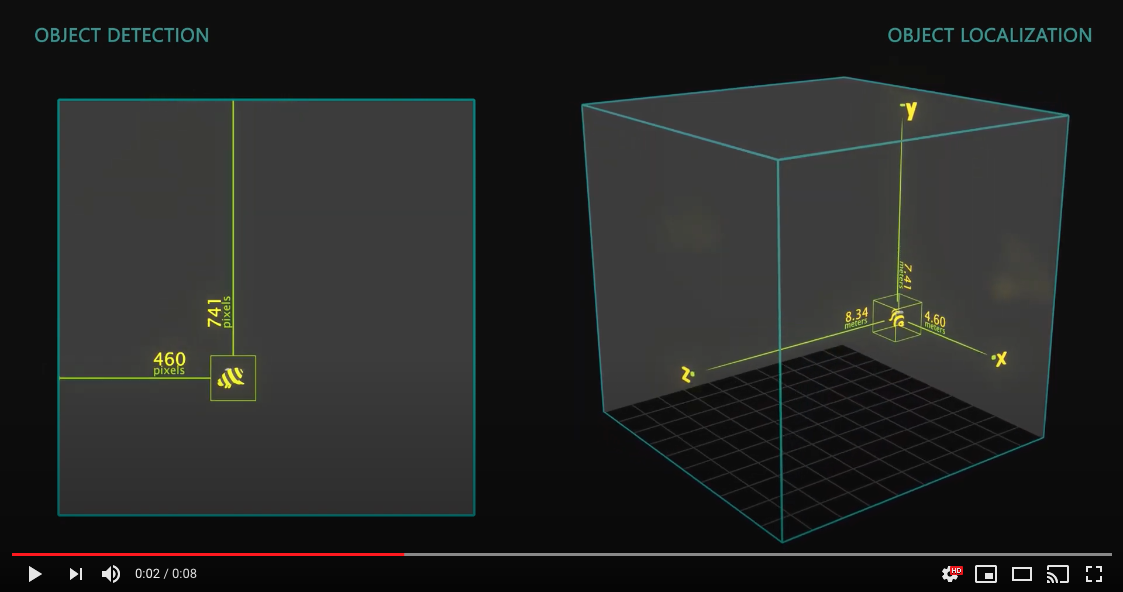
Spatial AI 是此类 2D 等效神经网络的超集,并使用空间信息进行扩展以为其提供 3D 上下文。 因此,换句话说,它不仅限于将对象检测器扩展到 3D 目标定位器。 其他网络类型也可以扩展,包括任何以以像素空间作为返回结果的网络。
这种扩展的示例是在 DepthAI 上使用面部特征检测器。 使用普通摄像头,该网络返回所有 45 个面部特征(眼睛,耳朵,嘴巴,眉毛等)的 2D 坐标。 使用与 DepthAI 相同的网络,这 45 个面部特征中的每一个现在都是物理空间中的 3D 点而不是像素空间中的 2D 点。
1.4. DepthAI 如何提供 Spatial AI 结果?
有两种方法可以使用 DepthAI 获得 Spatial AI 结果:
- 单目神经推理与双目深度的融合
在这种模式下,神经网络在单个相机上运行,并与视差深度结果融合在一起。 左,右或 RGB 相机可用于运行神经推理。
- 立体神经推理
在这种模式下,神经网络在左右双目相机上并行运行,以直接通过神经网络生成 3D 位置数据。
在这两种情况下,都可以使用标准神经网络。 无需使用 3D 数据训练神经网络。
在这两种情况下,DepthAI 都会使用标准的经过 2D 训练的网络自动提供 3D 结果,如 此处 所述。 这些模式具有不同的最小深度感知限制, 此处 有详细说明。
1.4.1. 单目神经推理与双目深度的融合
在这种模式下,DepthAI 在单个相机上运行目标检测(用户选择:左,右或 RGB ),并将结果与立体视差深度结果融合在一起。 立体视差结果是在 DepthAI 上(基于半全局匹配( SGBM ))实时并行生成的。
DepthAI 自动将视差深度结果与对象检测器结果融合在一起,并将每个对象的深度数据与已校准相机的已知内在函数结合使用,以重新投影检测对象在物理空间中的 3D 位置( X,Y,Z 坐标单位为米)。
所有这些计算都是在 DepthAI 上完成的,而没有任何其他系统的处理负担。 该技术对对象检测器非常有用,因为它提供了对象质心的物理位置 - 并利用了大多数对象通常为许多像素这一事实,因此可以对视差深度结果进行平均以产生更准确的位置。
该模式的可视化如下。
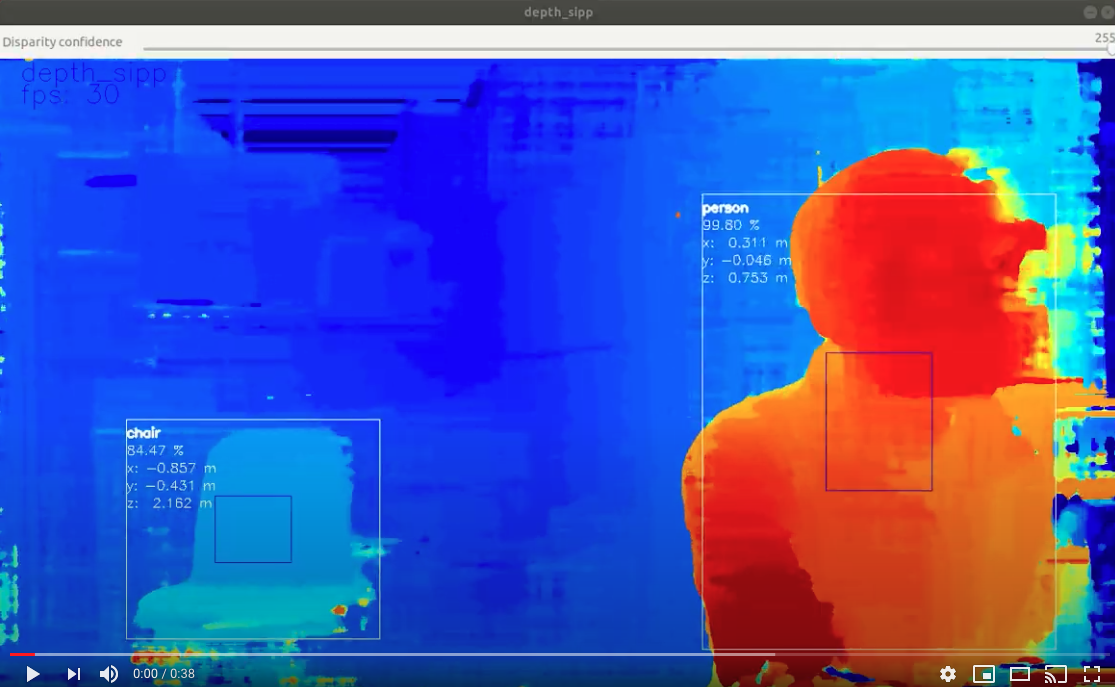
在这种情况下,神经推理( 此处 为物体检测示例 20 类)在 RGB 相机上运行,结果覆盖在深度流上。 DepthAI 参考 Python 脚本可用于显示此内容( python3 depthai_demo.py -s metaout depth -bb 是用于生成此视频的命令):
1.4.2. 立体神经推理
在这种模式下,DepthAI 在左右双目摄像头上并行运行神经网络。 然后将结果的差异与经过校准的相机内部函数(编程到每个 DepthAI 单元的 EEPROM 中)进行三角测量,以给出所有检测到的特征的 3D 位置。
这种 立体神经推理 模式可为网络提供准确的 3D 空间 AI,该网络可生成特征的单像素位置,例如面部特征估计,姿势估计或提供此类特征位置的其他元数据。
示例包括查找以下内容的 3D 位置:
面部特征(眼睛,耳朵,鼻子,嘴巴的边缘等)
产品的特征(螺丝孔,污点等)
人的关节(例如肘部,膝盖,臀部等)
车辆上的功能部件(例如后视镜,前照灯等)
植物上的病虫害或疾病(即特征对于物体检测 + 立体深度而言太小)
同样,此模式不需要使用深度数据训练神经网络。 DepthAI 采用标准的现成 2D 网络(这种情况更为常见),并使用此立体推断来生成准确的 3D 结果。
立体神经推理的示例如下。
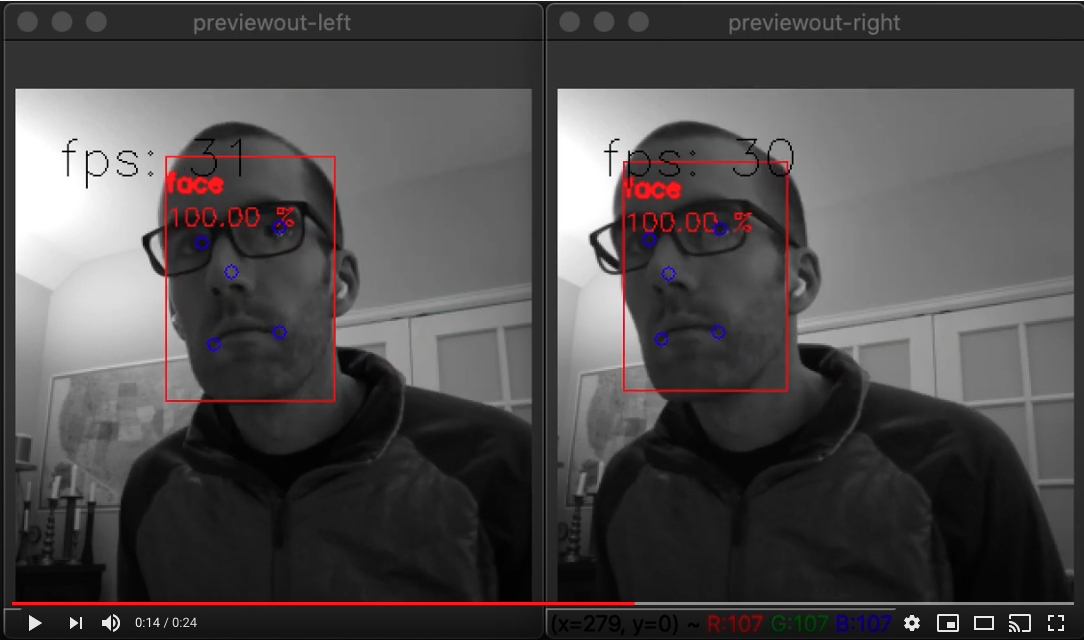
这实际上是一个有趣的案例,因为它在 DepthAI 上演示了两件事:
立体推理(即同时在左右两个摄像头上并行运行的神经网络)
多阶段推理(即面部检测后直接在 DepthAI 上进行面部特征点识别)
在 DepthAI 上运行此命令的命令是
python3 depthai_demo.py -cnn face-detection-retail-0004 -cnn2 landmarks-regression-retail-0009 -cam left_right -dd -sh 12 -cmx 12 -nce 2 -monor 400 -monof 30
其中 cam 指定要在两个相机上运行神经网络, -cnn 指定要运行的第一阶段网络(在这种情况下为人脸检测), -cnn2 指定第二阶段的网络(在这种情况下为面部特征检测),并且 -dd 禁用运行视差深度计算(因为在此模式下未使用它们)。
1.4.3. 注意
值得注意的是,对于像面部特征检测器,姿势估计器等返回单像素位置(而不是例如语义标记像素的边界框)的网络来说,单目神经推理与双目深度的融合模式的结果是可信的,但对于这些类型的网络建议采用立体神经推理来获得更好的结果,因为特征检测器不像对象检测器(对象通常覆盖许多像素,通常为数百个像素,可以将其平均化,以获得一个出色的深度/位置估计),标识检测器通常返回单像素位置。 因此,如果单个像素的立体视差结果不佳,那么位置可能是错误的。
所以立体神经推理模式在这些情况下表现出色,因为它根本不依赖于立体视差深度,而是纯粹依靠神经网络的结果,而神经网络在提供这些单像素结果方面非常可靠。 而左右并行输出的三角测量结果可在 3D 空间中得到非常准确的实时标识结果
1.5. 什么是 MegaAI ?
DepthAI 的单眼(单相机)版本是 MegaAI 。 因为并非所有解决嵌入式 AI / CV 问题的解决方案都需要空间信息。
我们将其命名为 mega 是因为它很小:

MegaAI 使用与 DepthAI 相同的所有硬件,固件,软件和训练堆栈(并使用相同的 DepthAI Githubs),它只是微小的单相机版本。
您可以从我们的分销商和我们的 在线商店 购买 MegaAI 。
1.6. 我应该订购哪种型号?
嵌入式 CV / AI 需要各种不同的形状/大小/排列。 因此,我们有多种选择可以满足这些需求。 以下是约10,000英尺选项的快速/直接摘要:
USB3 板载摄像头版 (BW1098OBC) - 非常适合在计算机上快速使用 DepthAI 。 所有相机均在板载,并且具有 USB3C 连接,可与任何 USB3 或 USB2 主机一起使用。
USB3 模块化相机版 (BW1098FFC) - 非常适合原型制作灵活性。 由于相机是模块化的,因此您可以将它们放置在各种立体基准上。 这种灵活性伴随着交易 - 您必须弄清楚如何/在哪里安装它们,然后在安装之后进行双目校准。 这不是一项繁重的工作,但请记住,它不像其他选项那样“即插即用” - 对于需要自定义安装,自定义基准线或自定义相机方向的应用程序来说更是如此。
MegaAI 单相机 (BW1093) - 就像 BW1098OBC 一样,但是对于那些不需要深度信息的人来说。 小型,即插即用的 USB3C AI / CV 相机。
Raspberry Pi 计算模块版 (BW1097) - 这个版本具有内置的 Raspberry Pi 计算模块 3B+。 因此,您实际上将其插入电源和 HDMI,然后启动,以展示 DepthAI 的功能。
具有 Wi-Fi / BT 的嵌入式 DepthAI (BW1092) - 目前,这是在 Alpha 测试中。 因此,只有在您熟悉尖端技术并希望帮助我们改进该产品时,才购买它。 它是 DepthAI 的第一个嵌入式(即 SPI 接口)版本 - 因此具有附加的 128MB NOR 闪存,因此它可以从 NOR 闪存中自行启动,并且不需要主机就可以运行。 相比之下,BW1097 也可以单独运行,但是它仍通过 Raspberry Pi 通过 USB 引导。 Myriad X 这款 BW1092 可以完全独立运行,而无需其他设备。 然后,内置的 ESP32 提供轻松/便捷的 WiFi / BT 支持以及流行的集成,例如即插即用的 AWS-IoT 支持,出色的 iOS / Android BT 示例等。
1.6.1. 模块系统
为了围绕 DepthAI 设计产品,我们提供模块系统。 然后,您可以利用我们的 开源硬件 设计自己的版本。 共有三个模块化系统可用:
BW1099 - 模块上的 USB 引导系统。 用于使设备通过 USB 连接到运行 Linux , macOS 或 Windows 的主机处理器。 在这种情况下,主机处理器将存储所有内容,并且 BW1099 可通过 USB 从主机启动。
BW1099EMB - NOR 闪存引导(也可以进行 USB 引导)。 用于制作独立运行的设备或与 ESP32 , AVR , STM32F4 等嵌入式 MCU 配合使用的设备。 如果需要,也可以通过 USB 引导。
BW2099 - NOR 闪存, eMMC , SD 卡和 USB 引导(可通过 2 个 100 针连接器上的 IO 选择)。 为了使设备独立运行并需要板载存储( 16GB eMMC )或以太网支持(通过 2 个 100 针连接器之一的板载 PCIE 接口,与具有以太网功能的基板配对,可提供以太网支持)。
1.7. 从头开始运行 DepthAI 有多困难? 支持哪些平台?
不难。 通常,DepthAI 会在几分钟之内在您的平台上启动/运行(其中大部分是下载时间)。 要求是 Python 和 OpenCV (无论如何,这对您的系统来说都是很棒的!)。 请参阅 此处 了解受支持的平台以及如何启动/运行它们。
Raspbian, Ubuntu, macOS, Windows, 以及其他许多功能均受支持,并且很容易启动/运行。 对于在各种平台上安装,请点击 此处。
在您选择的平台上,Spatial AI 的功能只需几分钟即可启动并运行。 下面是在 Mac 上运行的 DepthAI 。

(点击上图打开 YouTube 视频。)
获得以上输出的命令是
python3 depthai_demo.py -s metaout previewout depth -ff -bb
这是使用 pytyon3 depthai_demo.py -dd (以禁用显示深度信息)运行单相机版本( MegaAI ) :
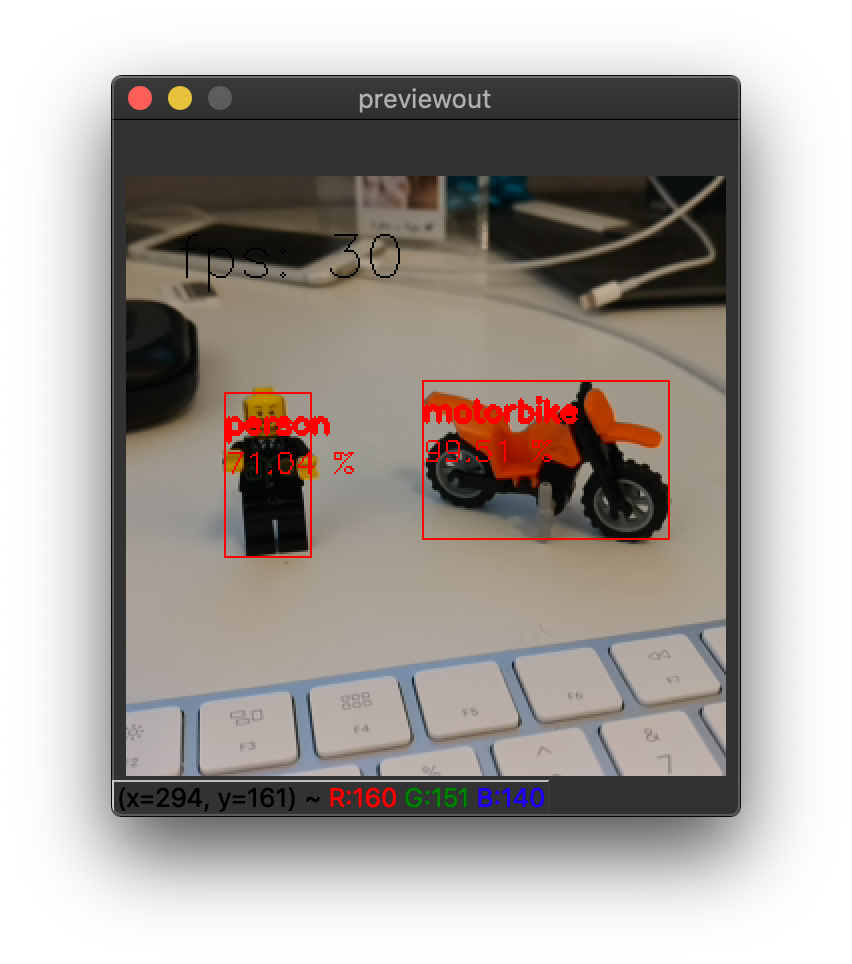
1.8. DepthAI 和 MegaAI 易于在 Raspberry Pi 中使用吗?
非常容易。 它旨在简化设置和使用,并保持 Pi CPU 的空闲。
请参阅 此处 以快速启动并运行!
1.9. Raspberry Pi 是否可以使用所有模型?
是的,可以使用每种模型,包括:
Raspberry Pi 计算模块版 (BW1097 - 这有一个内置的 Raspberry Pi 计算模块 3B+
Raspberry Pi HAT (BW1094) - 它的接口是 USB3 ,因此也可以与其他主机一起使用
USB3 板载摄像头版 BW1098OBC
USB3 模块化相机版C BW1098FFC
MegaAI 单相机 BW1093
我们甚至还有一些基本的 ROS 支持,也可以在 Pi 上使用。
1.10. DepthAI 是否可以在 NVIDIA Jetson 系列上使用?
是的,DepthAI 和 MegaAI 在所有 Jetson / Xavier 系列上都能正常工作,并且安装简便。 支持 Jetson Nano , Jetson Tx1 , Jetson Tx2 , Jetson Xavier NX , Jetson AGX Xavier 等。
有关在我的办公桌上运行的 Jetson Tx2 上运行的 DepthAI ,请参见下图·:
对于发行版,我们还将为aarch64构建预购建的轮子,因此将不需要以下编译步骤。但是要直接从GitHub出发,您可以使用以下命令在Jetson上安装: python3 -m pip install … 其中 … 是必要的DepthAI版本和提交,可能会成功的从源代码构建库。在此之前要检查的一件事是,您是否具有 cmake , libusb ( sudo apt install libusb-1.0-0-dev )和编译工具( sudo apt install build-essential )。
设置完成之后,也不要忘记udev规则:
echo 'SUBSYSTEM=="usb", ATTRS{idVendor}=="03e7", MODE="0666"' | sudo tee /etc/udev/rules.d/80-movidius.rules
sudo udevadm control --reload-rules && sudo udevadm trigger
1.11. 我可以在一台主机上使用多个 DepthAI 吗?
是的。 DepthAI 的架构是为了尽可能减少主机的负担。 因此,即使使用 Raspberry Pi ,您也可以在 Pi上 运行少数 DepthAI ,而不会给 Pi CPU 造成负担。
有关如何操作的说明,请参见 此处 。
1.12. DepthAI 与 OpenVINO 兼容吗?
是。 在撰写本文时,DepthAI 与 OpenVINO 2020.1 完全兼容。
Note
DepthAI Gen 2 支持 2020.1, 2020.2, 2020.3, 2020.4 和 2021.1。并且我们将竭尽全力支持新的OpenVINO版本。
1.13. 我能否在 DepthAI 上运行自己训练的模型?
当然。
我们提供了有关 Google Colab 笔记本的教程,您甚至可以使用它。 看 这里
1.14. 我需要深度数据来训练自己的 DepthAI 自定义模型吗?
不用。
这就是 DepthAI 的魅力所在。 它需要标准的物体检测器( 2D ,像素空间),并将这些神经网络与立体视差深度融合在一起,从而为您提供物理空间中的 3D 结果。
现在,您可以训练模型以利用深度信息吗? 是的,它可能比 2D 版本更准确。 为此,记录所有流(左,右和颜色)并对其进行重新训练(这需要修改 MobileNet-SSD 的前端以允许 5 层而不是 3 层(每个灰度 1 层, 3 层颜色R,G,B))。
1.15. 如果我训练自己的网络,DepthAI 支持哪些神经操作?
请参阅 此处 的 VPU 部分。
VPU 所支持的所有内容均可在 DepthAI 上使用。
值得注意的是,我们尚未测试所有这些排列。
1.16. DepthAI 支持哪些网络?
DepthAI 支持 此处 列出的所有网络。
我们还没有测试所有网络。 因此,如果您有任何问题,请与我们联系,我们将予以解决。
1.17. 我的模型需要预处理,如何在 DepthAI 中做到这一点
OpenVINO 工具包允许将这些预处理步骤添加到模型中,然后由 DepthAI 自动执行这些步骤。有关如何利用此优势的信息,请参见 此处 。
1.18. 我可以并行或串联(或同时运行)多个神经网络模型吗?
可以的。 第二代管道构建器 是让您能够执行此操作的方法。而且,在我们 depthai-experiments 存储库中有很多并行、串联或是并行+串联的示例实现。其中有一个值得注意的例子是凝时估计例子( 此处 ),在这个示例中同时展示了串联和并行。
1.19. DepthAI可以随意裁剪,调整大小,缩略图等吗?
是的,请参见 此处 ,以获取有关如何通过裁剪部分的WASD控件执行此操作的示例。并参见 此处 了解非矩形图形如何扩展,以及将其变形为矩形(这对于OCR很有用)。
1.20. DepthAI可以运行自定义CV代码吗?说来自PyTorch的CV代码?
是的,尽管我们还没有亲自这样做。但是社区中有人这样做了。Rahul Ravikumar就是其中之一,很高兴写下有关如何执行此操作的过程,请参见 此处 。然后可以将此代码作为 Gen2管道生成器 中的节点运行,与其他CV节点,神经推理,深度处理等配对。
1.21. 如何将 DepthAI 集成到我们的产品中?
如何集成 DepthAI / MegaAI 取决于您所构建的产品是否包括
运行操作系统( Linux , macOS 或 Windows )的处理器
没有操作系统的微控制器( MCU )(或类似 FreeRTOS 的 RTOS )
没有其他处理器或微控制器(即 DepthAI 是系统中唯一的处理器)。
我们提供支持所有 3 个用例的硬件,但是固件/软件的成熟度在以下 3 种模式下有所不同:
在所有情况下, DepthAI (和 MegaAI )都与 OpenVINO 兼容用于神经模型。 在模式之间唯一改变的是通信( USB ,以太网, SPI 等)以及所涉及的其他处理器(如果有)。
1.21.1. 用例 1: DepthAI / MegaAI 是运行 Linux , macOS 或 Windows 的处理器的协处理器。
在这种情况下, DepthAI 可以以两种方式使用:
1.21.2. 用例 2:将 DepthAI 与微控制器(如 ESP32,ATTiny8 等)结合使用
在这种情况下,DepthAI 从 BW1099EMB 上的内部闪存启动并通过 SPI 进行通信,从而允许 DepthAI 与诸如 STM32,MSP430,ESP32,ATMega / Arduino 等微控制器一起使用。我们甚至为 ESP32 ( BW1092 )提供了嵌入式参考设计可在我们的 商店 购买。 经过完全验证的设计也将开源(如果您需要设计文件,请与我们联系,然后再开源)。
用于此目的的代码库/ API 正在积极开发中,在撰写本文时, 此处 提供预发行版/ Alpha 版本。
1.21.3. 用例 3:将 DepthAI 用作设备上的唯一处理器。
支持通过在 Gen2 Pipeline Builder 中作为节点直接在 BW1099EMB 上运行 microPython 的操作。
microPython 节点允许自定义逻辑,驱动 I2C,SPI,GPIO,UART 等控件,允许直接控制执行器,直接从 CV / AI 功能流水线读取传感器等。 一个目标示例是使用 DepthAI 作为系统中唯一的处理器来构建整个自治的,视觉控制的机器人平台。
该模式的目标日期是 2020 年 12 月。
1.21.4. 每种用例的硬件:
BW1099: USB 启动。 因此,它旨在与运行 Linux,Mac 或 Windows 的主机处理器一起使用,并且该主机处理器通过 USB 启动 BW1099 。
BW1099EMB: USB 启动或 NOR 闪存启动。 该模块可以像 BW1099 一样与主机一起使用,但是还内置有 128MB NOR 闪存和板载启动开关 - 因此,可以对其进行编程以从 NOR 闪存而不是 USB 进行启动。 因此,这允许在完全不涉及操作系统的纯嵌入式应用程序中使用 DepthAI 。 因此,该模块可以与 ATTiny8 配对,例如通过 SPI 进行通信,或者与 BW1092 (预先安装了 BW1099EMB )上的 ESP32 配对。
1.21.5. 开发入门
无论打算将 DepthAI 与 具有 OS 的主机, 基于 SPI 的微控制器 (正在开发中)配合使用, 还是 完全独立 (针对目标支持,2020年12月) - 我们建议从 NCS2 模式 或 DepthAI USB API 开始进行原型/测试/等 。 因为它允许更快地迭代/反馈神经模型性能等。 特别是在 NCS2 模式下,所有图像/视频都可以直接从主机使用(这样,您就不必将相机对准要测试的物体)。
在 DepthAI 模式下,理论上将在 NCS2 模式下运行的任何东西都可以运行 - 但有时如果它是我们从未运行过的网络,则有时需要主机端处理 - 现在,它将仅在图像传感器之外运行(一旦 Gen2 管道构建器 计划于 2020 年 12 月发布,届时将具有使用 DepthAI API 在主机图像/视频上运行所有内容的功能)。 而且这项工作通常并不繁重…… 例如,我们之前从未通过 DepthAI API 来运行语义分段网络(因此没有这样做的参考代码),但是尽管如此,我们的一位用户没有我们帮助的情况下却在一天之内就可以工作了(例如此处)。
对于常见的对象检测器格式( MobileNet-SSD,tinyYOLOv1 / 2/ 3 等),实际上没有任何工作可以从 NCS2 模式转到 DepthAI 模式。 您可以从字面上替换我们拥有的 MobileNet-SSD 示例或 tinyYOLO 示例中的类。 例如,对于 tinyYOLOv3,您可以将标签从“ mask ”,“ no mask ”和“ no mask 2 ”更改为 此处 示例中的类,然后将 此处 的 blob 文件更改为您的 blob 文件。 对于 此处 的 MobileNet-SSD 同样如此。
1.22. DepthAI 和 MegaAI 中存在哪些硬件加速功能?
1.22.1. 目前在 DepthAI API 中可用:
神经推理(例如物体检测,图像分类等,包括两阶段,例如 此处 )
立体深度(包括中值滤波)(例如 此处)
立体推理(分两阶段进行,例如 此处)
对象跟踪(例如,此处 ,包括3D空间)
H.264 和 H.265 编码( HEVC,1080p 和 4K 视频,例如 此处)
JPEG 编码
MJPEG 编码
翘曲/变形
增强的视差深度模式(子像素,LR 检查和扩展视差), 此处
SPI 支持, 此处
任意裁剪 / 重定比例 / 重新格式化和 ROI 返回( 此处 )
以上功能在 Luxonis Pipeline Builder Gen1 中可用(请参见 此处 的示例)。 有关正在进行中的其他功能/灵活性的更多信息,请参见 Pipeline Builder Gen2 ,它将与下一代 DepthAI 的 Luxonis 管道生成器一起提供。
1.22.2. 在我们的路线图中(计划于 2020 年 12 月交付)
Pipeline Builder Gen2(神经网络和 CV 函数的任意串联/并联组合,在 此处 详细说明)
改进的立体神经推理支持( 此处 )
microPython 支持, 此处
特征跟踪( 此处 包括 IMU 辅助功能跟踪)
集成的 IMU 支持( 此处 )
运动估计( 此处 )
背景减去( 此处 )
无损变焦(从完整的 1200 万像素 到 4K ,1080p 或 720p , 此处 )
边缘检测( 此处 )
Harris 过滤( 此处 )
4月标签( PR )
集成文本检测 -> OCR 示例管道
OpenCL 支持(通过 OpenVINO 支持(此处 ))
在 此处 查看我们的 Github 项目,以跟踪这些实现的进展。
1.22.3. Gen2 管道构建器
我们一直在开发第二代管道构建器,它将把我们路线图中的许多特性整合到一个图形化的拖放 AI/CV 管道中,然后完全在 DepthAI 上运行,并将感兴趣的结果返回给主机。
这使得多级神经网络可以与 CV 函数 (如运动估计或 Harris 过滤) 和逻辑规则结合在一起,所有这些都在 DepthAI / MegaAI 上运行,而不会对主机造成任何负担。
1.23. CAD 文件是否可用?
是的。
所有载板的完整设计 (包括源 Altium 文件) 都在我们的 depthai-hardware Github 中
1.24. 如何使DepthAI感知更近的距离
如果近距离物体的深度结果看起来很奇怪,则可能是因为它们低于DepthAI/OAK-D的最小深度感知距离。
对于DepthAI车载摄像机(BW1098OBC)和OAK-D,标准设置的最小深度为70厘米左右。
可以使用以下选项将其切成1/2和1/4:
将分辨率更改为640*640,而不是标准的1280*1280。
由于96的视差搜索限制了最小深度,因此这意味着最小深度现在是标准设置的1/2-35cm而不是70cm。要使用示例脚本执行此操作,请运行 python3 depthai_demo.py -monor 400 -s Previewout metaout depth -bb 。在Gen1程序中,这是唯一的选择。但是在第二代管道构建器中,扩展视差可以再次将最小深度减少1/2。
启用扩展视差。
在Gen2中,支持扩展视差,这会将视差搜索范围从标准96像素扩展到192像素,从而将最小深度增加1/2倍,因此将BW1098OBC/OAK-D的最小深度设为1280*800分辨率和19.6左右时为35cm(受灰度相机的焦距限制),分辨率为640x400。
有关如何启用LR-Check的信息,请参见 此处示例 。
1.25. DepthAI 可见的最小深度是多少?
有两种方式可以使用 DepthAI 进行 3D 对象检测或使用神经信息来获得特征 (例如面部标识) 的实时 3D 位置:
单目神经推理与双目深度的融合
立体神经推理
1.25.1. 单目神经推理与双目深度的融合
在这种模式下,人工智能 (目标检测) 在左、右或 RGB 相机上运行,结果与基于半全局匹配 (SGBM) 的立体视差深度融合。 最小深度受限于最大视差搜索,默认为 96,但在扩展视差模式下可扩展到 192 (见下面的扩展视差)。 (请参见下面的 扩展视差 ) 。
要在此模式下计算最小距离,请使用以下公式,其中 BASE_LINE_DIST 和 MIN_DISTANCE 以米 [m] 为单位:
min_distance = focal_length * base_line_dist / 96
其中,96 是 DepthAI 使用的标准最大视差搜索,因此对于扩展视差 (192 像素),最小距离为:
min_distance = focal_length * base_line_dist / 192
对于 DepthAI 来说,灰度全球快门相机的 HFOV 是 73.5 度 (这可以在你的主板上找到,请看 这里 ,所以焦距是
focal_length = 1280/(2*tan(73.5/2/180*pi)) = 857.06
此处 计算 (对于视差深度数据,该值存储在 uint16 中,其中 uint16 的最大值 65535 是一个特定值,这意味着该距离是未知的。)
1.25.2. 立体神经推理
在这种模式下,神经推理 (目标检测、特征检测等)。 在左右摄像头上运行,以产生立体推断结果。 与融合了立体深度的单目神经推理不同 - 没有最大视差搜索限制 - 因此最小距离纯粹由 (a) 双目相机本身的水平视野 (HFOV) 和 (b) 相机的超焦距中较大者来限制。
全局快门双目相机的超焦距为 19.6 厘米。 因此,距离 19.6 厘米以下的物体会看起来是模糊的。 这实际上是此操作模式的最小距离,因为在大多数情况下 ( BW1098FFC 的非常宽的立体基线除外),此 有效 最小距离高于由于双目相机视野而产生的 实际 最小距离。 例如,当距离 BW1098OBC 小于 5.25 厘米 时,物体将完全处于两台灰度相机的视野之外,但这比灰度相机的超焦距更近 (19.6 厘米) ,所以实际的最小深度就是这个超焦距。
因此,要计算此操作模式的最小距离,请使用以下公式:
min_distance = max(tan((90-HFOV/2)*pi/2)*base_line_dist/2, 19.6)
这个公式实现了 HFOV 施加的最小距离的最大值,以及 19.6 厘米,这是超焦距施加的最小距离。
1.25.3. 板载相机最小深度
下面是视差深度和立体神经推理模式中可能的最小深度感知。
单目神经推理与双目深度的融合模式
对于装有板载相机的 DepthAI 单元,这可计算出以下最小深度:
DepthAI RPI 计算模块版本 (BW1097) 1280x800 双目相机分辨率的最小深度为 0.827 米,640x400 双目相机分辨率的最小深度为 0.414 米:
min_distance = 857.06 * 0.09 / 96 = 0.803 # m
计算在 这里
USB3C 板载摄像头版本 ( BW1098OBC) 是 0.669 米:
min_distance = 857.06*.075/96 = 0.669 # m
计算在 这里
立体神经推理模式
对于搭载相机的 DepthAI 单元,所有型号( BW1097 和 BW1098OBC ) 都受到双目摄像头超焦距的限制,因此它们的最小深度为 0.196 米。
1.25.4. 模块化相机最小深度:
下面是视差深度和立体神经推理模式中可能的最小深度感知。
单目神经推理与双目深度的融合模式
对于使用模块化相机的 DepthAI 设备,最小基线为 2.5 cm (见下图),这意味着全 1280x800 分辨率的最小可感知深度为 0.229 米,分辨率为 640x400 的最小可感知深度为 0.196 米 (与立体神经推理模式一样,受灰度相机的最小焦距限制)。
最小基线的设定仅仅取决于两块木板在物理干扰之前的间隔距离:

立体神经推理模式
对于 29 厘米以下的任何立体基线,最小深度由 19.6 厘米的超焦距 (物体被聚焦的距离) 决定。
对于宽度大于 29 厘米的立体基线,最小深度受水平视野 (HFOV) 限制:
min_distance = tan((90-HFOV/2)*pi/2)*base_line_dist/2
1.25.5. 扩展视差深度模式
如果您的应用程序对此感兴趣,我们可以实现一个称为 扩展视差 的系统,该系统为给定的基线提供更接近的最小距离。
这将最大视差搜索从 96 增加到 192。
因此,这会将最小可感知距离减半 (假设最小距离现在是 focal_length * base_line_dist / 192 ,而不是 focal_length * base_line_dist / 96).
DepthAI RPi 计算模块版本 (BW1097): 0.414 米
USB3C 板载摄像头版本 (BW1098OBC): 0.345 米
模块化相机的最小间距 (例如 BW1098FFC): 0.115 米
因此,如果您在使用融合了视差深度的单眼神经推理时需要更短的最小距离,请通过 SLACK、电子邮件或讨论网站与我们联系,让我们知道。它在我们的路线图上,但是我们尚未看到它的需求,因此我们还没有优先考虑实施它 (还没有!)
1.25.6. Left-Right Check Depth Mode
Left-Right Check或LR-Check用于删除由于对象边界处的遮挡而计算不正确的视差像素(左右相机视图略有不同)。
通过在 R->L 方向上匹配来计算视差
通过在 L->R 方向上匹配来计算视差
结合1和2的结果,在Shave上运行:每个像素 d = disparity_LR(x,y) 与 disparity_RL(xd,y) 进行比较。如果差值高于阈值,则最终视差图中 (x,y) 处的像素无效。
要在 DepthAI/OAK 上运行 LR-Check,请使用 此处 的示例。
1.26. DepthAI 最大可见深度是多少?
3D 物体检测的最大深度感知实际上受到物体检测器 (或其他神经网络) 能够检测到它所寻找的东西的距离的限制。 我们发现 OpenVINO 人类探测器工作在 22 米左右。 但通常情况下,这一距离将受到物体探测器可以探测到物体的距离的限制,然后是物体之间的最小角度差。
因此,如果目标探测器不是极限,最大距离将受到基线的物理特性和像素数的限制。 因此,一旦一个物体在一个相机和另一个相机之间相差小于 0.056 度 (相当于 1 个像素差),它就超过了可以实现全像素视差的点。 用于计算此距离的公式是近似值,但如下所示:
Dm = (baseline/2) * tan_d((90 - HFOV / HPixels)*pi/2)
对于深度 AI,HFOV=73.5 度,HPixels=1280。 而 BW1098OBC 的基线是 7.5 厘米。
因此,对现有模型使用此公式, 理论 最大距离为:
BW1098OBC( OAK-D; 基线 7.5 厘米):38.4 米
BW1097(基线 9 厘米):46 米
自定义基线:Dm =(基线 / 2)* tan_d(90 - 73.5 / 1280)
但由于视差匹配不完美,光学,图像传感器等也不是完美的,因此在现实世界中无法达到这些理论最大值,因此实际的最大深度将取决于照明,神经模型,特征尺寸,基线等。
在 KickStarter 活动 之后,我们还将支持子像素,这将扩展这一理论上的最大值,但同样,这很可能不是最大目标检测距离的实际限制,而是神经网络本身的限制。 这种子像素的使用可能会带来特定于应用的好处。
1.27. 深度流中的深度数据是什么格式?
输出数组位于 uint16 中,所以 0 到 65,535,直接映射为毫米(mm)。
所以阵列中 3141 的值就是 3141 毫米,也就是 3.141米。
所以这整个数组就是每个像素偏离相机平面的z维度,其中 宇宙的中心 就是标有 RIGHT 的相机。
而 65535 的具体数值是一个特殊值,意味着无效的视差/深度结果。
1.28. 如何计算视差的深度?
DepthAI 对于 深度 流和物体探测器 (如 MobileNet-SSD、YOLO 等) 都会转换为板载深度。
但是我们也允许检索实际视差结果,因此,如果您想直接使用视差图,则可以:
根据视差图计算深度图,就是(大约) baseline * focal / disparity。其中 BW1098OBC 的基线为 7.5cm, BW1092 的基线为 4.0cm,BW1097 的基线为 9.0cm,目前所有 DepthAI 模型的焦距为 857.06 (focal_length = 1280/(2*tan(73.5/2/180*pi)) = 857.06) 。
所以以 BW1092 为例(立体基线为 4.0cm ),视差测量为 60 就是深度为 58.8cm。 (depth = 40 * 857.06 / 60 = 571 mm (0.571m))。
1.29. 如何显示多个流 ?
要指定您希望显示哪些流,请使用 -s 选项。例如,对于元数据(如物体检测器的边界框结果)、颜色流( previewout)和深度结果( depth ),使用以下命令:
python3 depthai_demo.py -s metaout previewout depth
- 可用的流为:
metaout- 来自神经网络的元数据结果previewout- 彩色相机的少量预览流color- 4K 彩色相机,板上最大的带镜头的相机left- 左边的灰度相机(板上标有 L 或 LEFT )right- 右边的灰度相机(板上标有 R 或 RIGHT )rectified_left- 已整改的 左相机帧rectified_right- 已整改的 右相机帧depth- 深度,单位为 uint16 (格式见 这里 。)disparity- 原始视差disparity_color- 在主机上的色差(JET着色深度的可视化)meta_d2h- 设备芯片温度 (最高温度应小于 105 摄氏度)object_tracker- 对象跟踪器结果
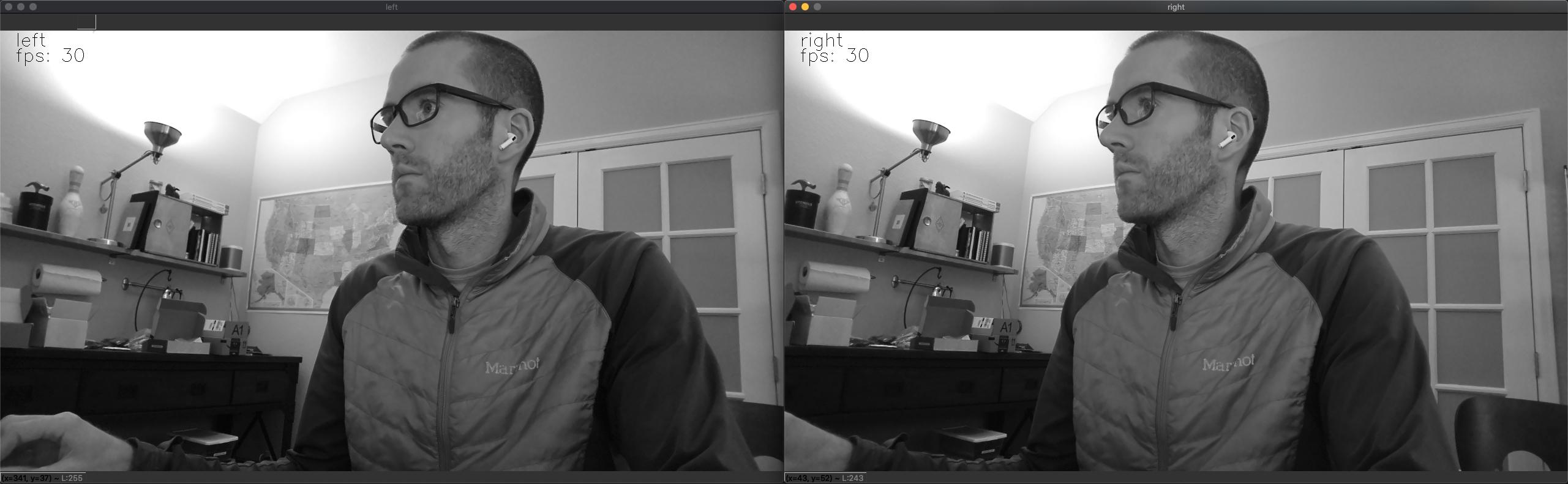
1.29.1. 是否可以访问主机上的原始双目相机视频流?
可以,要在主机上获取原始双目相机视频流,请使用以下命令:
python3 depthai_demo.py -s left right
这将显示完整的原始 (未压缩) 1280x720 双目相机视频流,如下所示:
1.30. 如何限制每个流的帧速率?
所以选择流的简单方法就是使用 -s 选项。
但是在某些情况下 (比如当您的主机运行速度很慢或者只有 USB2 连接时,你想显示大量的流),可能需要限制流的帧速度以避免主机 / USB2 承受过多的数据。
因此,如果要将流设置为特定的帧率,以减少 USB2 的负荷和主机负荷,只需用 -s streamname 指定流,并在流名称后加上逗号和 FPS,如 -s streamname,FPS.
因此,为了将 深度 限制在 5 FPS 以内,可以使用以下命令:
python3 depthai_demo.py -s depth,5
这同样适用于多个流:
python3 depthai_demo.py -s left,2 right,2 previewout depth,5
值得注意的是,帧速率限制在较低的速率下效果最好。 因此,如果您想要达到 25FPS,最好不要指定帧速率,而是让系统达到满 30FPS 。
不指定限制将默认为 30FPS 。
用户还可以使用以下覆盖命令结构,该结构允许您设置每个流的帧率。
下面的示例将 深度 流设置为 8 FPS , 预览值 设置为 12 FPS:
python3 depthai_demo.py -co '{"streams": [{"name": "depth", "max_fps": 8.0},{"name": "previewout", "max_fps": 12.0}]}'
您可以选择任何您想要的流,以及它们的帧速率,但是将额外的 {"name": "streamname", "max_fps": FPS} 粘贴到上面的表达式中。
1.31. 如何同步流/元数据(神经推理结果)
-sync 选项用于同步神经推理结果和它们运行的帧。当使用该选项时,设备端固件会尽最大努力按照元数据优先的顺序发送元数据和帧,紧接着是相应的图像。
当运行较重的立体神经推理时,特别是在主机负载较高的情况下,这个系统可能会崩溃,有两种方案可以保持同步:
将运行推理的摄像头的帧速率降低到神经推理本身的速度,或略低于神经推理本身的速度。
或者从结果(帧或元数据)中提取时间戳或序列号,并在主机上进行匹配。
1.31.1. 降低相机帧速率
在神经模型不能以 30FPS 全速执行的情况下,会导致缺乏同步性,特别是在使用这些模型在左右灰度图像传感器上并行运行立体神经推理的情况下。
恢复同步的一个简单 / 容易的方法是降低帧率,使其与神经推理的帧率相匹配,或者刚好低于神经推理的帧率。
这可以通过命令行使用 -rgbf 和 -monof 命令来实现。
例如,要运行一个默认模型,将 RGB 和两个灰度相机都设置为 24FPS,使用以下命令。
./depthai_demo.py -rgbf 24 -monof 24 -sync
1.31.2. 在主机上同步
可以使用 FrameMetadata.getTimestamp() 和 FrameMetadata.getSequenceNum() 两种方法来保证主机端的同步。
NNPackets 和 DataPackets 从设备端分开发送,在主机端进入每个流的单独队列。
函数 CNNPipeline.get_available_nnet_and_data_packets() 会返回函数被调用时队列中可用的内容(可能是只有一个 NN 包未读,或者只有一个帧包)。
通过 depthai.py 中的 -sync 选项,我们在设备端(即在 Myriad X 上)尽最大努力同步 NN 和 previewout,并按顺序发送:首先发送 NN 数据包(在 depthai.py 中,它被保存为最新的),然后发送 previewout 帧(在 depthai_demo.py 中接收时,最新保存的 NN 数据会被叠加上去)。
在大多数情况下,这样做的效果很好,但是有一个风险(特别是在主机端系统负载较高的情况下),由于队列由不同的线程 (在 C++ 库中) 处理,因此数据包可能仍然不同步。
所以在这种情况下, getMetadata().getTimestamp() 会返回设备时间(以秒为单位,以浮点数表示),并且在 双目校准脚本 中用于同步左右帧。
时间戳对应的是相机拍摄到的帧的时刻,并通过管道转发。
而方法 getMetadata().getSequenceNum() 会返回每个相机帧的递增数。
相同的数字与 NN 数据包相关联,所以它可能是一个更容易使用的选项,而不是比较时间戳。NN数据包和数据包的序列号应该匹配。
另外,左右两个摄像头的序列号相同 (时间戳不是完全相同的,而是相隔几微秒 – 这是因为时间戳是由不同的中断处理程序分别分配给每个相机的。但这两台相机是同时使用 I2C 广播写启动的,也使用相同的 MCLK 源,所以应该不会偏差)。
在这种情况下,我们还需要检查 NN 和数据包的相机来源。
目前,depthai.py 使用 getMetadata().getCameraName() 来实现这个目的,它返回一个字符串: rgb, left 或 right .
也可以使用 getMetadata().getInstanceNum(),分别返回一个数字:0、1 或 2。
1.32. 如何使用 DepthAI 录制(或编码)视频?
- DepthAI 本身直接支持 h.264 和 h.265(HEVC)以及 JPEG 编码 - 无需任何主机支持。
depthai_demo.py 脚本展示了如何访问这个功能的例子。
要从命令行利用这一功能,请使用 -v (或 --video)命令行参数,如下所示:
python3 depthai_demo.py -v [path/to/video.h264]
然后使用下面的命令播放 mp4 / mkv 格式的视频:
ffmpeg -framerate 30 -i [path/to/video.h264] -c copy [outputfile.mp4/mkv]
默认情况下,每隔 1 秒就有一个关键帧,这解决了之前遍历视频的问题,同时也提供了随时开始录制的能力(最坏的情况下,如果错过了关键帧,1 秒的视频就会丢失)
当运行 depthai_demo.py 时,可以通过在键盘上按 c 键来记录当前帧的 jpeg。
下面是一个在 DepthAI BW1097 ( Raspberry Pi 计算模块版)上编码的视频示例。 所有的 DepthAI 和 MegaAI 单元都有相同的 4K 彩色摄像头,因此将具有与下面视频相当的性能。

1.32.1. 视频编码选项
通过在 DepthAI 管道构建器的 JSON 配置中添加 video_config 部分,可以在视频编码系统中配置额外的选项,JOSN配置在 此处 , 这里 有一个示例。
config = {
...
'video_config':
{
'rateCtrlMode': 'cbr', # 选项: 'cbr' / 'vbr' (恒定比特率或可变比特率)
'profile': 'h265_main', # 选项: 'h264_baseline' / 'h264_main' / 'h264_high' / 'h265_main'
'bitrate': 8000000, # 使用 CBR 时
'maxBitrate': 8000000, # 使用 CBR 时
'keyframeFrequency': 30, # 帧数
'numBFrames': 0,
'quality': 80 # (0 - 100%) 使用 VBR 时
}
...
}
上面的选项是当前公开的所有视频编码选项,并不是所有选项都必须设置。
如果配置字典中 不 存在 video_config ,则使用默认值:H264_HIGH,恒定比特率 8500Kbps,每 30 帧关键帧 (每秒一次),B 帧数:0
1.33. 什么是流延迟?
在实现机器人或机电系统时,了解从照片击中图像传感器到用户获得结果所需的时间,即 photon-to-results ,通常是相当有用的。
所以下面的结果是这个 photon-to-results 的近似值,很可能是一个高估的结果,因为我们测试的时候是通过实际看到结果在显示器上更新的时间,而显示器本身也有一定的延迟,所以下面的结果可能被我们在测试期间使用的监视器的延迟高估了。
自这些测量以来,我们还进行了几次优化,因此延迟可能会比这些要低得多。
测量 |
要求 |
平均延迟,毫秒 |
|---|---|---|
left |
left |
100 |
left |
left, right |
100 |
left |
left, right, depth |
100 |
left |
left, right, depth, metaout, previewout |
100 |
previewout |
previewout |
65 |
previewout |
metaout, previewout |
100 |
previewout |
left, right, depth, metaout, previewout |
100 |
metaout |
metaout |
300 |
metaout |
metaout, previewout |
300 |
metaout |
left, right, depth, metaout, previewout |
300 |
1.34. 可以将 RGB 相机/双目相机作为普通的 UVC 相机使用吗?
是的,但目前尚未在我们的 API 中实现。 在我们的路线图上, 此处
原因 是我们的 DepthAI API 在格式上提供了更多的灵活性(未编码、编码、元数据、处理、帧率等),并且已经可以在任何操作系统上使用 (这里)。
因此,我们计划支持 UVC 作为我们的 Gen2 管道构建器的一部分,这样您就可以构建一个复杂的空间 AI/CV 管道,然后让 UVC 端点输出结果,这样 DepthAI 就可以在任何系统上工作,而不需要驱动。对于我们的嵌入式版本,可以将其闪存到设备上,这样整个管道将在启动时自动运行,并向计算机显示一个 UVC 设备 (网络摄像机)。
理论上,我们可以为 3 个相机中的每一个实现对 3 个 UVC 端点的支持(所以显示为 3 个 UVC 相机)。
我们已经使用内部概念验证(但是是灰度的)制作了 2 倍的原型,但还没有尝试过 3 倍,但它可能会工作。 如果有兴趣的话,我们可以支持每台相机的 UVC 流。
所以,如果你想要这个功能,请在 这里 订阅 Github 功能请求。
1.35. 如何强制使用 USB2 模式?
如果你想使用超长的 USB 数据线,并且不需要 USB3 的速度,那么 USB2 通信可能是可取的。
要强制使用 USB2 模式,只需使用 -fusb2 (或 --force_usb2) )命令行选项,如下所示:
python3 depthai_demo.py -fusb2
请注意,如果您想要在比 USB2 所能处理的距离更远的距离上使用 DepthAI, 我们将推出 DepthAI PoE 版本,请参见 此处 , 它允许 DepthAI 使用长达 328.1 英尺(100 米)的数据线,以每秒1千兆比特(1Gbps)的速度提供数据和电源。
1.36. 什么是「 NCS2 模式」 ?
所有 DepthAI / MegaAI 的版本都支持我们所说的 “NCS2 模式”。这使得 MegaAI 和 DepthAI 可以假装成一个 NCS2。
因此,事实上,如果你给你的设备供电,将其插入电脑,并按照带有 OpenVINO 的 NCS2 的说明、示例等进行操作,DepthAI /MegaAI 将表现得和 NCS2 完全一样。
这允许你直接试用 OpenVINO 的例子,就像我们的硬件是一个 NCS2 一样。 这在实验模型时很有用,因为这些模型被设计成在你可能没有本地(物理上)可用的对象(项目)上操作。 它还允许以程序化的方式运行推理,以保证质量,完善模型性能等,因为在这种模式下,图像是从主机推送的,而不是从板载相机拉来的。
DepthAI / MegaAI 还将在 Gen2 管道生成器 中支持额外的主机通信模式,该模式将于 2020 年 12 月推出。
1.37. DepthAI 板上存储了哪些信息?
最初的 Crowd Supply 支持者收到的电路板上几乎没有任何存储。 所有信息都从主机加载到板子上。 这包括 BW1097 (BW1097),它的校准存储在附带的 microSD 卡上。
因此,每个拥有的双目相机硬件型号(如 BW1097 、
BW1098FFC 、 BW1098OBC 和
BW1094 )都有能力存储校准数据和视野、立体基线( L-R distance ) 和彩色相机与双目相机的相对位置( L-RGB distance)
as well as camera orientation (L/R swapped )。
要检索这些信息,只需运行 python3 depthai_demo.py 并查找 EEPROM data: 即可。
从 BW1098OBC 中提取的信息示例如下:
EEPROM data: valid (v2)
Board name : BW1098OBC
Board rev : R0M0E0
HFOV L/R : 73.5 deg
HFOV RGB : 68.7938 deg
L-R distance : 7.5 cm
L-RGB distance : 3.75 cm
L/R swapped : yes
L/R crop region: top
Calibration homography:
1.002324, -0.004016, -0.552212,
0.001249, 0.993829, -1.710247,
0.000008, -0.000010, 1.000000,
目前 (2020 年 4 月及以后) 装有板载双目相机( BW1097, BW1098OBC 和 BW1092 ) 的 DepthAI 主板,其板载校准和主板参数已预先编程到DepthAI 的主板 eeprom 中。
1.38. 双匀质成像与单匀质成像校准
由于从 OpenCV 空间人工智能竞赛 中获得了一些巨大的反馈/见解,我们发现并实现了许多有用的功能(在 此 总结)。
其中一个发现是,双匀质成像法虽然在数学上等同于单匀质成像法 (因为你可以将两个方法合并为一个),但在现实世界的实践中实际上优于单匀质成像法。
因此,我们在 2020 年 9 月将校准系统改为使用双均相而非单均相。因此,2020 年 9 月之后生产的任何产品都包含双匀质成像法。任何使用单匀质成像法的产品都可以重新校准( 这里 ),以使用更新的双匀质成像法校准。
1.39. 什么是 DepthAI 和 MegaAI 的视野?
DepthAI 和 MegaAI 使用相同的基于 IMX378 的 1200 万像素 RGB 摄像头模块。
1200 万像素 RGB 水平视野(HFOV):68.7938 度
100 万像素全局快门灰度相机水平视野(HFOV):73.5 度
1.40. 如何获得 DepthAI 和 MegaAI 的不同视野或镜头?
ArduCam 正在制作各种专门用于 DepthAI h和 MegaAI 的相机模块,包括各种 M12-mount 选项(因此用户可以改变光学器件/视角等)。
有了这些,视角、焦距、滤光(红外、无红外、NDVI 等)和图像传感器格式将有多种选择。
1.41. DepthAI 和 MegaAI 的最高分辨率和录制 FPS 是多少?
MegaAI 可用于流式传输 USB3 的原始/非压缩视频。 Gen1 USB3 的速率为 5gbps,Gen2 USB3 的速率为 10gbps。 DepthAI 和 MegaAI 能够支持 Gen1 和 Gen2 USB3 - 但并不是所有的 USB3 主机都支持 Gen2,所以请检查你的主机规格,看看是否可以使用 Gen2 速率。
分辨率 |
USB3 Gen1 (5gbps) |
USB3 Gen2 (10gbps) |
|---|---|---|
12MP (4056x3040) |
21.09fps (390MB/s) |
41.2fps (762MB/s) |
4K (3840x2160) |
30.01fps (373MB/s) |
60.0fps (746MB/s) |
DepthAI 和 MegaAI 可以在设备上进行 h.264 和 h.265(HEVC)编码。 最大分辨率 / 速率为 4K,30FPS。 使用 DepthAI / MegaAI 中的默认编码设置,吞吐量将从 373MB/s (原始 / 未编码 4K/30) 降至 3.125MB/s (H.265/HEVC,25mbps比特率)。 下面是一个在 DepthAI BW1097 (Raspberry Pi 计算模块版)上编码的视频示例:

值得注意的是,所有 DepthAI 和 MegaAI 产品共享相同的彩色相机规格和编码功能。 因此,在 DepthAI 设备上使用彩色相机拍摄的画面与使用 MegaAI 设备拍摄的画面完全相同。
- 编码方式:
1200 万像素 (4056x3040) :JPEG 图片 / 静止图像
4K (3840x2160) :30.00fps (3.125MB/s)
1.42. 有多少算力可用?有多少神经算力可用?
DepthAI 和 MegaAI 是围绕英特尔 Movidius Myriad X 构建的。有关这一部分的更多详细信息 / 背景,请单击 此处 和 此处 。
- DepthAI / MegaAI 硬件 / 计算能力简介:
总计算量:4 万亿次 / 秒 (最多 4 次)
神经计算引擎 (总共 2 倍):最多 1.4 个 (仅限神经计算)
16 个 SHAVES:最多 1 个可用于额外的神经计算或其他 CV 功能 (例如通过 OpenCL OpenCL)
20 + 个专用硬件加速计算机视觉块,包括视差深度、特征匹配 / 跟踪、光流、中值滤波、哈里斯滤波、翘曲 / 去翘曲、H.264/H.265/JPEG/MJPEG 编码、运动估计等。
总处理速度超过 5 亿像素 / 秒 (请参阅 此处 的 USB 最高分辨率和帧率)
450 GB / 秒内存带宽
512 MB LPDDR4 (如有兴趣,请联系我们获取 1GB LPDDR 版本)
1.43. 支持哪些自动对焦模式?可以从主机控制自动对焦吗?
DepthAI 和 MegaAI 支持连续视频自动对焦(下面的’2’,系统会不断自主搜索最佳对焦),也支持 auto 模式(下面的’1’),该模式等待主机指示后再对焦。
(增加该功能的 PR 在 这里 。)
示例用法见 depthai_demo.py 。
当运行 python3 depthai_demo.py 时,可以在程序运行时通过键盘命令使用该功能:
‘1’ 将自动对焦模式更改为自动
‘f’ 触发自动对焦
‘2’ 将自动对焦模式更改为连续视频
你可以在 这里 看到参考的 DepthAI API 调用
1.44. 自动对焦彩色相机的超焦距是多少?
超焦距很重要,因为超过这个距离,所有的东西都能很好地聚焦。一些人将此称为 “无限焦点” (Infinity Focus)。
DepthAI / MegaAI 的彩色相机模块的 “超焦距”(H)由于其 f.no 和焦距的关系,相当接近。
从 维基百科 上看,超焦距如下:
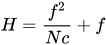
其中:
f = 4.52mm (相机模块的 “有效焦距”)
N = 2.0 (+/- 5%, FWIW)
c = 0.00578mm (看 这里 ,有人拼出了 1/2.3” 格式, ,这是 IMX378 的传感器格式)
所以 H = (4.52mm)^2/(2.0 * 0.00578mm) + 4.52mm ~= 1,772mm, 或 1.772 米 (5.8 英尺).
我们使用的是有效焦距,由于我们不是光学专家,我们不能 100% 确定这样做是否合适,但是彩色模块的总高度是 6.05 毫米,所以用这个作为最坏情况下的焦距,仍然可以得到 10.4 英尺 的超焦距。
那么,这对您的应用程序意味着什么呢?
当对焦设置为 10 英尺或更远时,任何距离 DepthAI / MegaAI 超过 10 英尺的东西都会被对焦。 换句话说,只要你没有比 10 英尺更近的东西被相机对焦,10 英尺或更远的东西都会被对焦。
1.45. 是否可以从主机控制 RGB 相机的曝光、白平衡和自动对焦 (3A) 设置?
1.45.1. 自动对焦 (AF)
点击 这里 了解控制自动对焦 / 对焦的详细信息。
1.45.2. 曝光 (AE)
可以通过 API 设置帧持续时间(us)、曝光时间(us)、感光度(iso)。 而且我们为彩色相机提供了一个小例子 https://github.com/luxonis/depthai/pull/279 ,以展示如何针对彩色相机执行这些操作
我们计划让这些控件更具自文档化功能 (参见 此处 ),但与此同时,所有可用的控件都在这里 https://github.com/luxonis/depthai-shared/blob/82435d4/include/depthai-shared/metadata/camera_control.hpp#L107
例如,要将曝光时间设置为 23.4 毫秒,最大感光度为 1600,请使用:
self.device.send_camera_control(
depthai.CameraControl.CamId.RGB,
depthai.CameraControl.Command.AE_MANUAL,
"23400 1600 33333")
1.45.3. 白平衡 (AWB)
这将在曝光的同时实施,并将包括在内。 AWB 锁定,AWB 模式。 在我们深入研究这项任务时,我们将发布更多信息。
1.46. 全局快门灰度相机的规格是什么?
该双目相机由基于 ov9282 的全局同步快门相机模块组成。
- 规格说明:
有效焦距 (EFL): 2.55
F 数 (F.NO): 2.2 +/- 5%
视野 (FOV): - 对角线 (DFOV): 82.6(+/- 0.5) 度 - 水平 (HFOV): 73.5(+/- 0.5) 度 - 垂直 (VFOV): 50.0(+/- 0.5) 度
失真度: < 1%
镜头尺寸: 1/4 英寸
对焦方式: 固定对焦,0.196 米(超焦距)至无限远
分辨率: 1280 x 800 像素
像素大小: 3x3 微米 (um)
1.47. 我可以在相机上安装备用镜头吗?什么样的接口? S 型? C 型?
MegaAI 和 DepthAI 上的彩色摄像头是一个完全集成的摄像头模块,所以镜头、自动对焦、自动对焦电机等都是自成一体的,,都是不可更换和维修的。 你会发现它的体积都非常小。 这和你在高端智能手机上看到的摄像头是一样的。
因此,如果您要使用自定义光学器件,例如具有IR功能,UV能力,不同视场(FOV)等功能,建议的方法是使用OV9281和/或IMX477模块的ArduCam M12或CS安装系列。
请注意,这些是需要一个适配器的( 此处 )以及 below 的适配器。并且此适配器连接到BW1098FFC的RGB端口。可以制造其他适配器,以便一次可以使用多个这样的摄像机,也可以修改 开源 BW1098FFC 以直接接受ArduCam FFC,但尚未完成。
尽管如此,我们已经看到用户在智能手机上安装了同样的光学元件来扩大视野、变焦等。 通过这些转接板,自动对焦似乎可以很好地工作。 例如有团队成员在 这里 测试了 Occipital 广角镜头 可以与 MegaAI 和 DepthAI 彩色相机配合使用。(我们还没有在灰度相机上试过)。
另外,有关将 DepthAI FFC 与 RPi HQ 相机配合使用以启用 C 型和 CS 型镜头的信息,请参见 下文 。
1.48. 我可以完全通过 USB 为 DepthAI 供电吗?
USB3 (能够提供 900 mA) 能够为 DepthAI 模型提供足够的功率。然而,USB2 (能够提供 500 mA) 则不是。 因此,在 DepthAI 模型上,电源由 5V 桶插孔电源提供,以防止 DepthAI 插入 USB2 并因 USB2 电源电量不足 (即断电) 而出现间歇性行为的情况。
要完全通过 USB 为您的 DepthAI 供电 (假设您相信您的端口可以提供足够的电力),您可以使用 此处 的桶插孔适配器 USB-A 数据线。 我们经常使用 DepthAI 与 这个 USB 移动电源一起使用 。
1.49. 如何在 VirtualBox 下使用 DepthAI
如果要使用 VirtualBox 运行 DepthAI 源代码,请确保允许虚拟机访问 USB 设备。 另外,请注意,默认情况下,它仅支持 USB 1.1 设备,并且 DepthAI 分两个阶段运行:
对于插入时显示。我们使用这个端点将固件加载到设备上,这是一种 usb-boot 技术。这个设备是 USB2 的。
用于运行实际的代码。这个在 usb 启动后显示出来,是 usb3。
为了支持 DepthAI 模式,您需要下载并安装 Oracle VM VirtualBox Extension Pack 。 安装后,在USB设置中启用USB3(xHCI)控制器。
完成此操作后,您需要将Myriad作为USB设备从主机路由切到VBox。这是在启动之前对DepthAI的过滤器,当时是USB2设备:
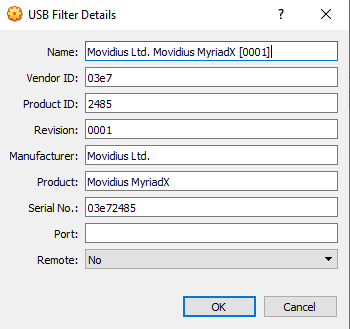
最后一步是添加USB Intel Loopback设备。DepthAI设备通过USB引导其固件,并在启动后显示为新设备。
当DepthAI/OAK-D试图重新连接时(在运行时,因此在管道建立之后,如 :bash: python3 depthai_demo.py ),此设备将刚刚显示。
可能需要花费一些尝试才能显示和添加此回送设备,因为在管道建立之后,DepthAI尝试连接时,您需要执行此操作(因此,此时它已通过USB2引导其内部固件)。
如果仅启用一次,则可以在此处(在管道启动之后)看到回送设备:
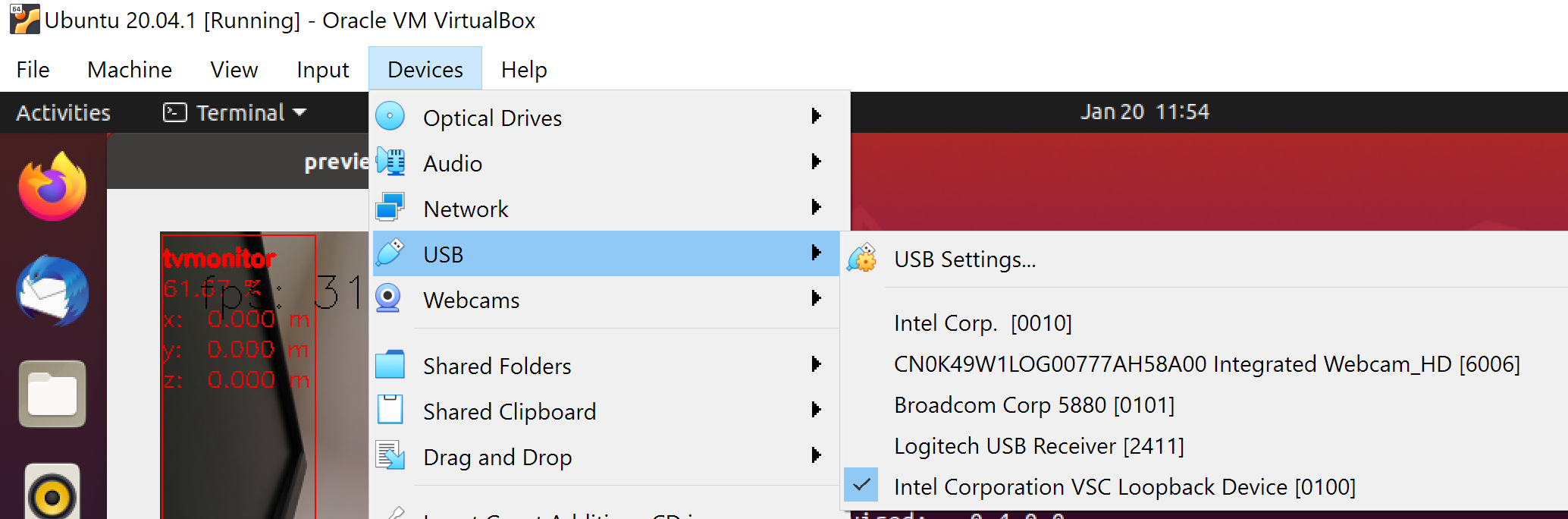
然后要永久启用此直通虚拟盒,请在以下设置中启用此功能:
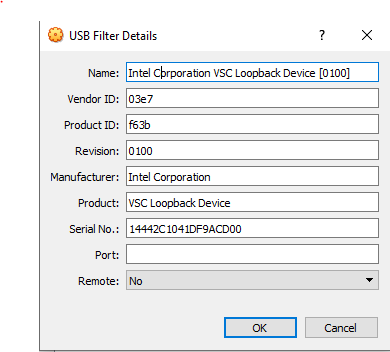
然后,对于您要通过的每个其他DepthAI/OAK设备,对每个单元重复此最后的回送设置步骤(因为每个单元都有其自己的唯一ID)。
1.50. 如何提高 NCE、SHAVES 和 CMX 参数?
如果你想指定使用神经计算引擎(NCE),SHAVE 核,Connection MatriX 块 的个数,你可以通过 DepthAI 来实现。
我们已经在示例脚本中实现了 -nce, -sh 和 -cmx 命令行参数。
只需克隆 DepthAI 仓库 然后执行以下操作
./depthai_demo.py -nce 2 -sh 14 -cmx 14
而它将运行默认的使用 2 个 NCE,14 个 SHAVE 和 14 个 CMX 编译的 MobilenetSSD。 注意,这些值 不能大于上面可以看到 的值,所以不能使用 15 个 SHAVE 或 3 个 NCE。 14 是 SHAVE 和 CMX 参数的极限,2 是 NCE 的极限。
您可以按照 本地 OpenVINO 模型转换教程 或使用我们的 在线 MyriadX blob 转换器 来自己尝试
1.51. 我可以将 DepthAI 与新的 RPi HQ 相机一起使用吗?
DepthAI FFC 版( 此处 为 BW1098FFC 型号)也可通过转接板与 Raspberry Pi HQ 相机(基于 IMX477)一起使用,然后可与大量 C 型和 CS 型镜头(请参见 此处 )一起使用。 并在 此处 查看 DepthAI FFC 版的转接板。

这是 DepthAI 的一个特别有趣的应用,因为它允许 RPi HQ 相机被编码为 h.265 4K 视频(和 1200 万像素的静态照片), 即使是 Raspberry Pi 1 或 Raspberry Pi Zero - 因为 DepthAI 做了所有的板载编码 - 所以 Pi 只接收 3.125 MB/s 编码的 4K H.265 流,而不是直接从 IMX477 上获得的 373MB/s 4K 原始流(这对 Pi 来说数据量太大,无法处理,这也是为什么当 Pi 直接与 Pi HQ 相机一起使用时,只能进行1080p视频而不能进行4K视频录制)。
下面是它的一些快速展示的图片和视频:



您可以在 此处 购买适用于 DepthAI FFC 版(BW1098FFC)的转接板套件
1.52. 我可以将 DepthAI 与 Raspberry Pi Zero 一起使用吗?
是的,DepthAI 在 Raspberry Pi Zero 上是完全可以使用的,您可以看到以下示例:


感谢 Connor Christie 帮助搭建了这个布景!
1.53. DepthAI RPi CME 的耗电量是多少?
The DepthAI Raspberry Pi 计算模块版 (简称 RPI CME 或 BW1097) 的空闲功耗约为 2.5W,当 DepthAI 满负荷运行时,功耗为 5.5W 至 6W。
Idle: 2.5W (0.5A @ 5V)
DepthAI Full-Out: 6W (1.2A @ 5V)
下面是一段快速展示的视频:

1.54. 如何获得更短或更长的柔性扁平数据线 (FFC)?
对于灰度相机,我们使用 0.5 mm、20 针的同侧接触挠性数据线。
对于 RGB 相机,我们使用 0.5 mm、26 针的同侧接触挠性数据线。
您可以直接购买 Molex 的 15166 系列 FFC ,以支持更短或更长的长度。 确保你得到 同侧 触点,Molex 称之为 “Type A”
1.55. meta_d2h 返回的 CSS MSS UPA 和 DSS 是什么?
CSS: CPU 子系统(主核)
MSS: 媒体子系统
UPA: 微处理器(UP)阵列 – Shaves
DSS: DDR 子系统
1.56. Githubs 地址在哪里?DepthAI 是开源的吗?
DepthAI 是跨各种协议栈的开源平台,包括硬件(电气和机械),软件以及使用 Google Colab 进行的机器学习训练。
请看下面的相关 Githubs:
1.56.1. 整体
https://github.com/luxonis/depthai-hardware - DepthAI 硬件设计本身
https://github.com/luxonis/depthai - Python 演示和示例
https://github.com/luxonis/depthai-python - Python API
https://github.com/luxonis/depthai-api - C++ Core 和 C++ API
https://github.com/luxonis/depthai-ml-training - 利用 Google Colab 进行在线 AI/ML 训练(所以是免费的)
https://github.com/luxonis/depthai-experiments - 展示如何使用 DepthAI 的实验
1.56.2. 嵌入式应用案例
https://github.com/luxonis/depthai-spi-api - 用于嵌入式(微控制器)DepthAI 应用的 SPI 接口库
https://github.com/luxonis/depthai-bootloader-shared - Bootloader 源码,允许对 DepthAI 的 NOR 闪存进行编程,以便自主启动
https://github.com/luxonis/depthai-experiments/tree/depthai-experiments-spi/gen2-spi - ESP32 嵌入式及ESP32 DepthAI 使用的 ESP32 应用实例(如与 BW1092 一起使用)
1.57. 我可以在 DepthAI 上使用 IMU 吗?
是的,我们的 BW1099 ( 这里)已经支持与 IMU 交互。 我们正在开发内置 BNO085 的 BW1098OBC (以及 BW1092) 的未来版本。 我们尚未在 DepthAI API 中添加对这种 IMU 的支持,但我们已经做了概念验证,并将通过 API 使之成为标准功能。
1.58. 产品手册和数据表在哪里?
1.58.1. 产品手册:
1.58.2. 数据表:
1.59. 如何在出版物中引用 luxonis 产品?
如果您的研究中大量使用了 DepthAI 和 OAK-D 产品,并且您想在您的学术出版物中答谢 DepthAI 和 OAK-D 产品,我们建议使用以下 bibtex 格式引用。
@misc{DepthAI,
title={ {DepthAI}: Embedded Machine learning and Computer vision api},
url={https://luxonis.com/},
note={Software available from luxonis.com},
author={luxonis},
year={2020},
}
@misc{OAK-D,
title={ {OAK-D}: Stereo camera with Edge AI},
url={https://luxonis.com/},
note={Stereo Camera with Edge AI capabilites from luxonis and OpenCV},
author={luxonis},
year={2020},
}
1.60. 如何与工程师交流?
在 Luxonis,我们坚信客户能够与我们的工程师直接沟通的价值 - 它有助于提高我们的工程效率。 它使我们以重要的方式(即以正确的方式实现可用性)来解决实际问题。
- 因此,我们有许多机制来实现直接沟通:
Luxonis Community Discord. 使用它与我们的工程师进行实时交流。我们甚至可以在这里为您的项目/工作建立专门的公开或私密通道,以便根据需要进行讨论。
Luxonis GitHub. 欢迎在任何/所有相关仓库中提出 GitHub issues,并提出问题、功能请求或问题报告。我们通常会在几小时内做出回应(通常在几分钟内)。关于我们的 Githubs 摘要,请看 这里。
discuss.luxonis.com. 用来开始任何公开讨论、想法、产品请求、支持请求等,或者与 Luxonis 社区进行交流。当您在这里的时候,请在 这里 查看这个由 DepthAI 为视障人士制作的超棒的视觉辅助设备。
有疑问?
我们很乐意为您提供代码或其他问题的帮助。



我们的联系方式



还可以通过我们发布的视频和文章了解OAK


