Device¶
Device is an OAK camera or a RAE robot. On all of our devices there’s a powerful Robotics Vision Core (RVC). The RVC is optimized for performing AI inference, CV operations, and for processing sensory inputs (eg. stereo depth, video encoders, etc.).
Device API¶
Device object represents an OAK device. When starting the device, you have to upload a Pipeline to it, which will get executed on the VPU.
When you create the device in the code, firmware is uploaded together with the pipeline and other assets (such as NN blobs).
pipeline = depthai.Pipeline()
# Create nodes, configure them and link them together
# Upload the pipeline to the device
with depthai.Device(pipeline) as device:
# Print MxID, USB speed, and available cameras on the device
print('MxId:',device.getDeviceInfo().getMxId())
print('USB speed:',device.getUsbSpeed())
print('Connected cameras:',device.getConnectedCameras())
# Input queue, to send message from the host to the device (you can receive the message on the device with XLinkIn)
input_q = device.getInputQueue("input_name", maxSize=4, blocking=False)
# Output queue, to receive message on the host from the device (you can send the message on the device with XLinkOut)
output_q = device.getOutputQueue("output_name", maxSize=4, blocking=False)
while True:
# Get a message that came from the queue
output_q.get() # Or output_q.tryGet() for non-blocking
# Send a message to the device
cfg = depthai.ImageManipConfig()
input_q.send(cfg)
Connect to specified device¶
If you have multiple devices and only want to connect to a specific one, or if your OAK PoE camera is outside of your subnet, you can specify the device (either with MxID, IP, or USB port name) you want to connect to.
# Specify MXID, IP Address or USB path
device_info = depthai.DeviceInfo("14442C108144F1D000") # MXID
#device_info = depthai.DeviceInfo("192.168.1.44") # IP Address
#device_info = depthai.DeviceInfo("3.3.3") # USB port name
with depthai.Device(pipeline, device_info) as device:
# ...
Host clock syncing¶
When depthai library connects to a device, it automatically syncs device’s timestamp to host’s timestamp. Timestamp syncing happens continuously at around 5 second intervals, and can be configured via API (example script below).
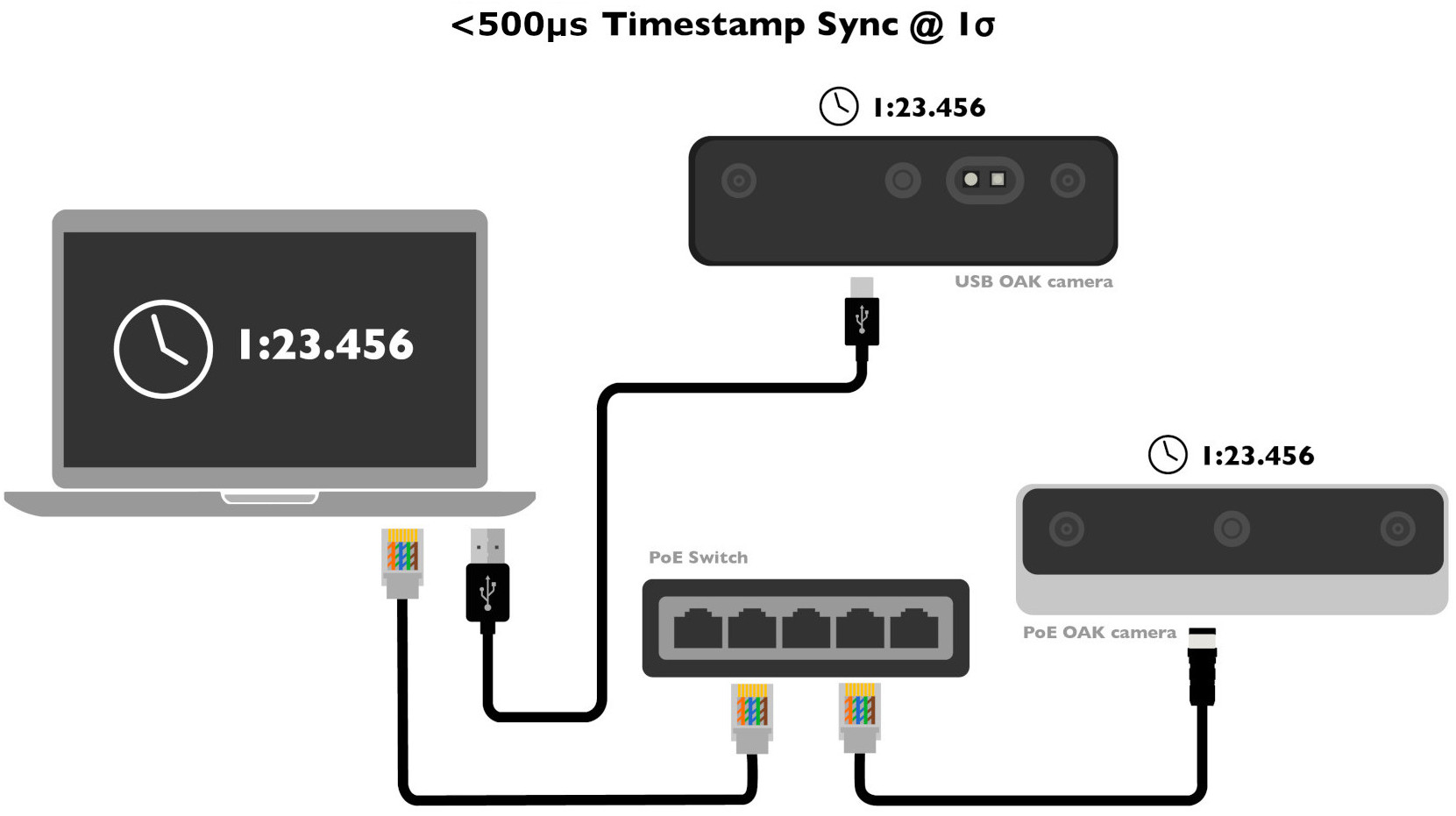
Device clocks are synced at below 500µs accuracy for PoE cameras, and below 200µs accuracy for USB cameras at 1σ (standard deviation) with host clock.
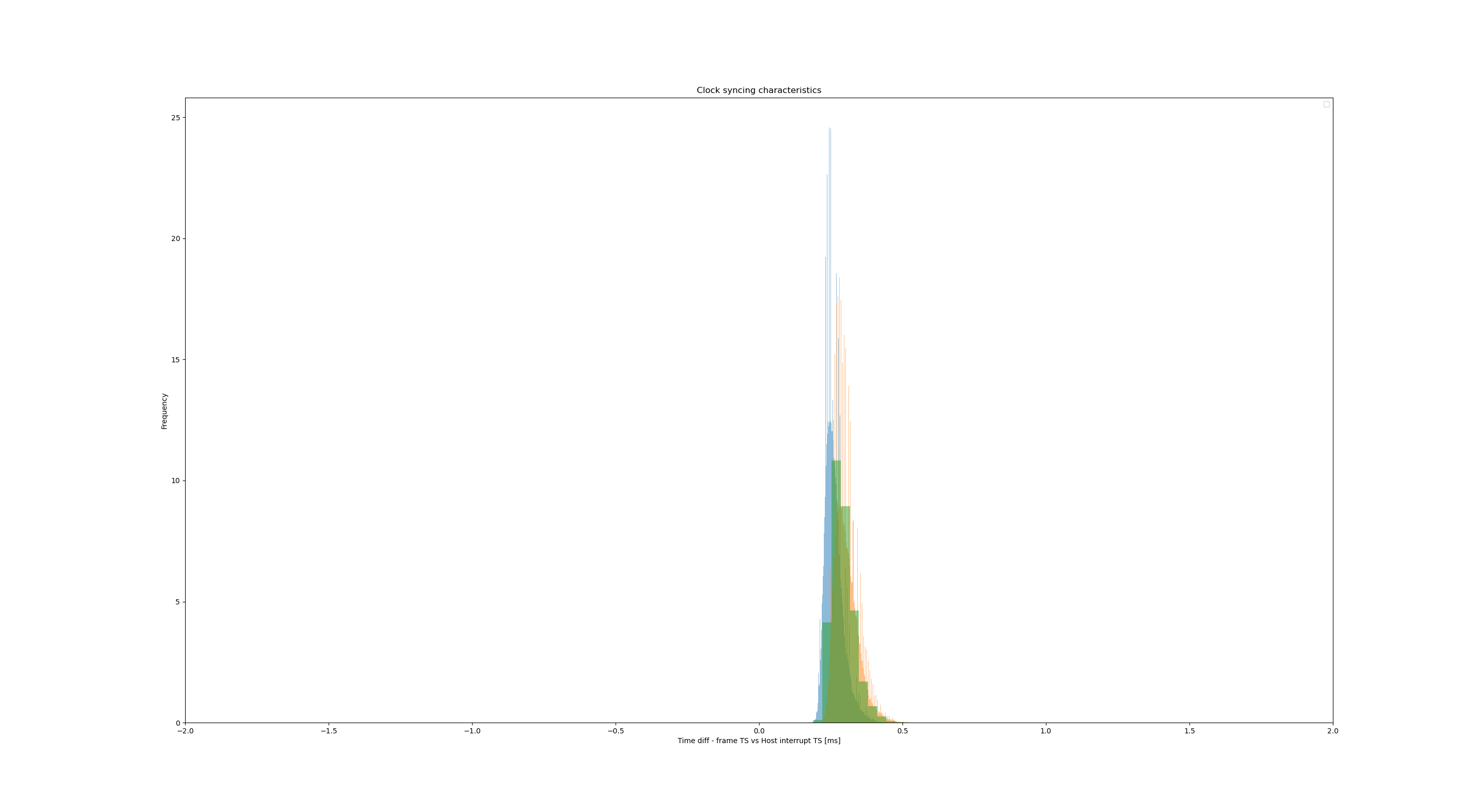
Above is a graph representing the accuracy of the device clock with respect to the host clock. We had 3 devices connected (OAK PoE cameras), all were hardware synchronized using FSYNC Y-adapter. Raspberry Pi (the host) had an interrupt pin connected to the FSYNC line, so at the start of each frame the interrupt happened and the host clock was recorded. Then we compared frame (synced) timestamps with host timestamps and computed the standard deviation. For the histogram above we ran this test for approximately 3 hours.
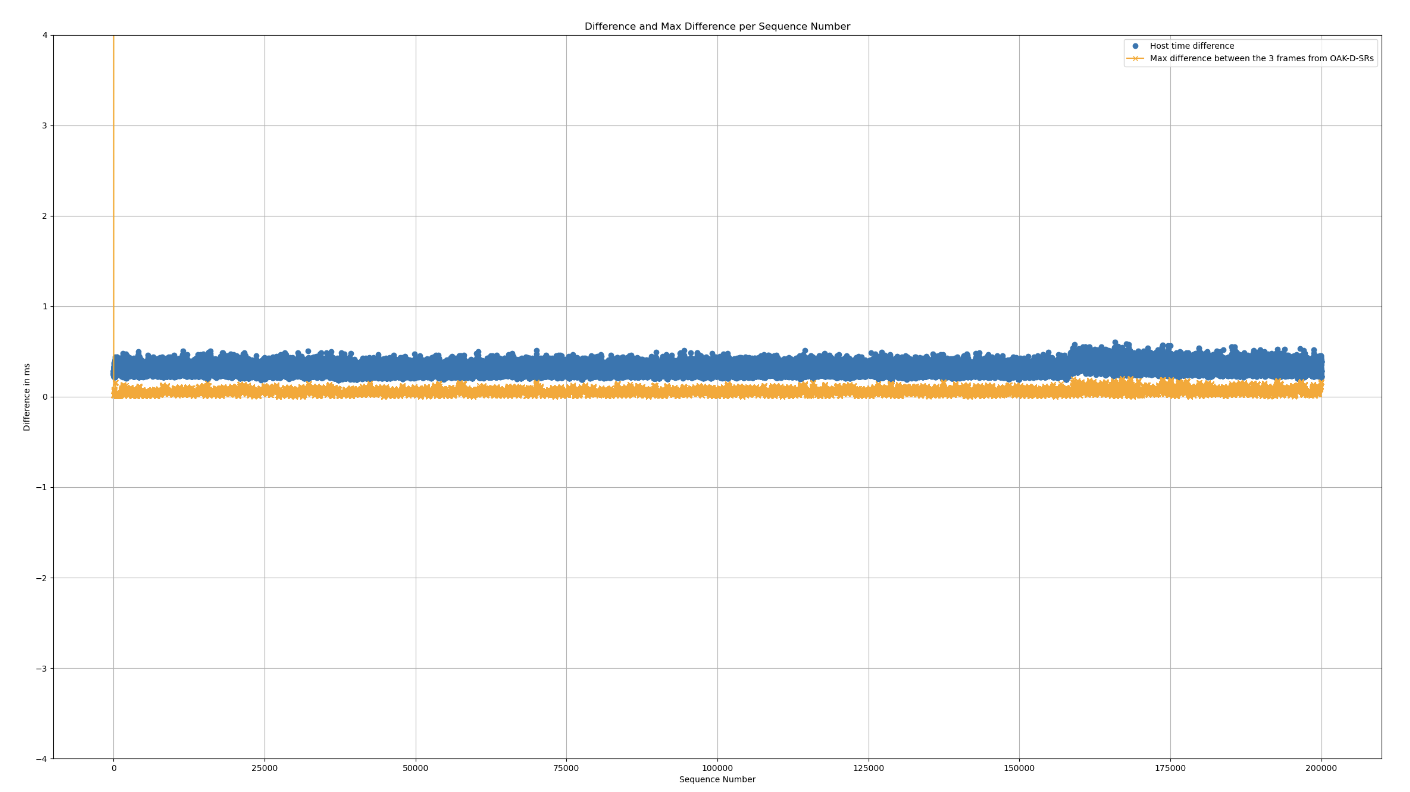
Below is a graph representing the difference between the device and host clock. The graph shows the difference between the device and host clock over time. The graph is a result of the same test as the previous one.
# Configure host clock syncing example
import depthai as dai
from datetime import timedelta
# Configure pipeline
with dai.Device(pipeline) as device:
# 1st value: Interval between timesync runs
# 2nd value: Number of timesync samples per run which are used to compute a better value
# 3rd value: If true partial timesync requests will be performed at random intervals, otherwise at fixed intervals
device.setTimesync(timedelta(seconds=5), 10, True) # (These are default values)
Multiple devices¶
If you want to use multiple devices on a host, check Multiple DepthAI per Host.
Device queues¶
After initializing the device, you can create input/output queues that match XLinkIn/XLinkOut nodes in the pipeline. These queues will be located on the host computer (in RAM).
pipeline = dai.Pipeline()
xout = pipeline.createXLinkOut()
xout.setStreamName("output_name")
# ...
xin = pipeline.createXLinkIn()
xin.setStreamName("input_name")
# ...
with dai.Device(pipeline) as device:
outputQueue = device.getOutputQueue("output_name", maxSize=5, blocking=False)
inputQueue = device.getInputQueue("input_name")
outputQueue.get() # Read from the queue, blocks until message arrives
outputQueue.tryGet() # Read from the queue, returns None if there's no msg (doesn't block)
if outputQueue.has(): # Check if there are any messages in the queue
When you define an output queue, the device can push new messages to it at any time, and the host can read from it at any time.
Output queue - maxSize and blocking¶
When the host is reading very fast from the queue (inside while True loop), the queue, regardless of its size, will stay empty most of the time. But as we add things on the host side (additional processing, analysis, etc), it may happen that the device will be pushing messages to the queue faster than the host can read from it. And then the messages in the queue will start to increase - and both maxSize and blocking flags determine the behavior of the queue in this case. Two common configurations are:
with dai.Device(pipeline) as device:
# If you want only the latest message, and don't care about previous ones;
# When a new msg arrives to the host, it will overwrite the previous (oldest) one if it's still in the queue
q1 = device.getOutputQueue(name="name1", maxSize=1, blocking=False)
# If you care about every single message (eg. H264/5 encoded video; if you miss a frame, you will get artifacts);
# If the queue is full, the device will wait until the host reads a message from the queue
q2 = device.getOutputQueue(name="name2", maxSize=30, blocking=True) # Also default values (maxSize=30/blocking=True)
We used maxSize=30 just as an example, but it can be any int16 number. Since device queues are on the host computer, memory (RAM) usually isn’t that scarce, so maxSize wouldn’t matter that much. But if you are using a small SBC like RPI Zero (512MB RAM), and are streaming large frames (eg. 4K unencoded), you could quickly run out of memory if you set maxSize to a high value (and don’t read from the queue fast enough).
Some additional information¶
Queues are thread-safe - they can be accessed from any thread.
Queues are created such that each queue is its own thread which takes care of receiving, serializing/deserializing, and sending the messages forward (same for input/output queues).
The
Deviceobject isn’t fully thread-safe. Some RPC calls (eg.getLogLevel,setLogLevel,getDdrMemoryUsage) will get thread-safe once the mutex is set in place (right now there could be races).
Watchdog¶
The watchdog is a crucial component in the operation of POE (Power over Ethernet) devices with DepthAI. When DepthAI disconnects from a POE device, the watchdog mechanism is the first to respond, initiating a reset of the camera. This reset is followed by a complete system reboot, which includes the loading of the DepthAI bootloader and the initialization of the entire networking stack.
The watchdog process is necessary to make the camera available for reconnection and typically takes about 10 seconds, which means the fastest possible reconnection time is 10 seconds.
Customizing the Watchdog Timeout¶
Set the environment variables DEPTHAI_WATCHDOG_INITIAL_DELAY and DEPTHAI_BOOTUP_TIMEOUT to your desired timeout values (in milliseconds) as follows:
DEPTHAI_WATCHDOG_INITIAL_DELAY=<my_value> DEPTHAI_BOOTUP_TIMEOUT=<my_value> python3 script.py
For Windows PowerShell, set the environment variables like this:
$env:DEPTHAI_WATCHDOG_INITIAL_DELAY=<my_value>
$env:DEPTHAI_BOOTUP_TIMEOUT=<my_value>
python3 script.py
In Windows CMD, you can set the environment variables as follows:
set DEPTHAI_WATCHDOG_INITIAL_DELAY=<my_value>
set DEPTHAI_BOOTUP_TIMEOUT=<my_value>
python3 script.py
Alternatively, you can set the timeout directly in your code:
pipeline = depthai.Pipeline()
# Create a BoardConfig object
config = depthai.BoardConfig()
# Set the parameters
config.watchdogInitialDelayMs = <my_value>
config.watchdogTimeoutMs = <my_value>
pipeline.setBoardConfig(config)
By adjusting these settings, you can tailor the watchdog functionality to better suit your specific requirements.
Environment Variables¶
The following table lists various environment variables used in the system, along with their descriptions:
Environment Variable |
Description |
|---|---|
DEPTHAI_LEVEL |
Sets logging verbosity, options: ‘trace’, ‘debug’, ‘warn’, ‘error’, ‘off’ |
XLINK_LEVEL |
Sets logging verbosity of XLink library, options: ‘debug’, ‘info’, ‘warn’, ‘error’, ‘fatal’, ‘off’ |
DEPTHAI_INSTALL_SIGNAL_HANDLER |
Set to 0 to disable installing Backward signal handler for stack trace printing |
DEPTHAI_WATCHDOG |
Sets device watchdog timeout. Useful for debugging (DEPTHAI_WATCHDOG=0), to prevent device reset while the process is paused. |
DEPTHAI_WATCHDOG_INITIAL_DELAY |
Specifies delay after which the device watchdog starts. |
DEPTHAI_SEARCH_TIMEOUT |
Specifies timeout in milliseconds for device searching in blocking functions. |
DEPTHAI_CONNECT_TIMEOUT |
Specifies timeout in milliseconds for establishing a connection to a given device. |
DEPTHAI_BOOTUP_TIMEOUT |
Specifies timeout in milliseconds for waiting the device to boot after sending the binary. |
DEPTHAI_PROTOCOL |
Restricts default search to the specified protocol. Options: any, usb, tcpip. |
DEPTHAI_DEVICE_MXID_LIST |
Restricts default search to the specified MXIDs. Accepts comma separated list of MXIDs. Lists filter results in an “AND” manner and not “OR” |
DEPTHAI_DEVICE_ID_LIST |
Alias to MXID list. Lists filter results in an “AND” manner and not “OR” |
DEPTHAI_DEVICE_NAME_LIST |
Restricts default search to the specified NAMEs. Accepts comma separated list of NAMEs. Lists filter results in an “AND” manner and not “OR” |
DEPTHAI_DEVICE_BINARY |
Overrides device Firmware binary. Mostly for internal debugging purposes. |
DEPTHAI_BOOTLOADER_BINARY_USB |
Overrides device USB Bootloader binary. Mostly for internal debugging purposes. |
DEPTHAI_BOOTLOADER_BINARY_ETH |
Overrides device Network Bootloader binary. Mostly for internal debugging purposes. |
Reference¶
-
class
depthai.Device -
addLogCallback(self: depthai.DeviceBase, callback: Callable[[depthai.LogMessage], None]) → int
-
close(self: depthai.DeviceBase) → None Closes the connection to device. Better alternative is the usage of context manager: with depthai.Device(pipeline) as device:
-
factoryResetCalibration(self: depthai.DeviceBase) → None
-
flashCalibration(self: depthai.DeviceBase, calibrationDataHandler: depthai.CalibrationHandler) → bool
-
flashCalibration2(self: depthai.DeviceBase, arg0: depthai.CalibrationHandler) → None
-
flashEepromClear(self: depthai.DeviceBase) → None
-
flashFactoryCalibration(self: depthai.DeviceBase, arg0: depthai.CalibrationHandler) → None
-
flashFactoryEepromClear(self: depthai.DeviceBase) → None
-
static
getAllAvailableDevices() → list[depthai.DeviceInfo]
-
static
getAllConnectedDevices() → list[depthai.DeviceInfo]
-
static
getAnyAvailableDevice(*args, **kwargs) Overloaded function.
getAnyAvailableDevice(timeout: datetime.timedelta) -> tuple[bool, depthai.DeviceInfo]
getAnyAvailableDevice() -> tuple[bool, depthai.DeviceInfo]
-
getAvailableStereoPairs(self: depthai.DeviceBase) → list[depthai.StereoPair]
-
getBootloaderVersion(self: depthai.DeviceBase) → Optional[depthai.Version]
-
getCameraSensorNames(self: depthai.DeviceBase) → dict[depthai.CameraBoardSocket, str]
-
getChipTemperature(self: depthai.DeviceBase) → depthai.ChipTemperature
-
getCmxMemoryUsage(self: depthai.DeviceBase) → depthai.MemoryInfo
-
getConnectedCameraFeatures(self: depthai.DeviceBase) → list[depthai.CameraFeatures]
-
getConnectedCameras(self: depthai.DeviceBase) → list[depthai.CameraBoardSocket]
-
getConnectedIMU(self: depthai.DeviceBase) → str
-
getConnectionInterfaces(self: depthai.DeviceBase) → list[depthai.connectionInterface]
-
getCrashDump(self: depthai.DeviceBase, clearCrashDump: bool = True) → depthai.CrashDump
-
getDdrMemoryUsage(self: depthai.DeviceBase) → depthai.MemoryInfo
-
static
getDeviceByMxId(mxId: str) → tuple[bool, depthai.DeviceInfo]
-
getDeviceInfo(self: depthai.DeviceBase) → depthai.DeviceInfo
-
getDeviceName(self: depthai.DeviceBase) → object
-
static
getEmbeddedDeviceBinary(*args, **kwargs) Overloaded function.
getEmbeddedDeviceBinary(usb2Mode: bool, version: depthai.OpenVINO.Version = <Version.???: 7>) -> list[int]
getEmbeddedDeviceBinary(config: depthai.Device.Config) -> list[int]
-
getEmbeddedIMUFirmwareVersion(self: depthai.DeviceBase) → depthai.Version
-
static
getFirstAvailableDevice(skipInvalidDevices: bool = True) → tuple[bool, depthai.DeviceInfo]
-
static
getGlobalProfilingData() → depthai.ProfilingData
-
getIMUFirmwareUpdateStatus(self: depthai.DeviceBase) → tuple[bool, int]
-
getIMUFirmwareVersion(self: depthai.DeviceBase) → depthai.Version
-
getInputQueue(*args, **kwargs) Overloaded function.
getInputQueue(self: depthai.Device, name: str) -> depthai.DataInputQueue
getInputQueue(self: depthai.Device, name: str, maxSize: int, blocking: bool = True) -> depthai.DataInputQueue
-
getInputQueueNames(self: depthai.Device) → list[str]
-
getLeonCssCpuUsage(self: depthai.DeviceBase) → depthai.CpuUsage
-
getLeonCssHeapUsage(self: depthai.DeviceBase) → depthai.MemoryInfo
-
getLeonMssCpuUsage(self: depthai.DeviceBase) → depthai.CpuUsage
-
getLeonMssHeapUsage(self: depthai.DeviceBase) → depthai.MemoryInfo
-
getLogLevel(self: depthai.DeviceBase) → depthai.LogLevel
-
getLogOutputLevel(self: depthai.DeviceBase) → depthai.LogLevel
-
getMxId(self: depthai.DeviceBase) → str
-
getOutputQueue(*args, **kwargs) Overloaded function.
getOutputQueue(self: depthai.Device, name: str) -> depthai.DataOutputQueue
getOutputQueue(self: depthai.Device, name: str, maxSize: int, blocking: bool = True) -> depthai.DataOutputQueue
-
getOutputQueueNames(self: depthai.Device) → list[str]
-
getProductName(self: depthai.DeviceBase) → object
-
getProfilingData(self: depthai.DeviceBase) → depthai.ProfilingData
-
getQueueEvent(*args, **kwargs) Overloaded function.
getQueueEvent(self: depthai.Device, queueNames: list[str], timeout: datetime.timedelta = datetime.timedelta(days=-1, seconds=86399, microseconds=999999)) -> str
getQueueEvent(self: depthai.Device, queueName: str, timeout: datetime.timedelta = datetime.timedelta(days=-1, seconds=86399, microseconds=999999)) -> str
getQueueEvent(self: depthai.Device, timeout: datetime.timedelta = datetime.timedelta(days=-1, seconds=86399, microseconds=999999)) -> str
-
getQueueEvents(*args, **kwargs) Overloaded function.
getQueueEvents(self: depthai.Device, queueNames: list[str], maxNumEvents: int = 18446744073709551615, timeout: datetime.timedelta = datetime.timedelta(days=-1, seconds=86399, microseconds=999999)) -> list[str]
getQueueEvents(self: depthai.Device, queueName: str, maxNumEvents: int = 18446744073709551615, timeout: datetime.timedelta = datetime.timedelta(days=-1, seconds=86399, microseconds=999999)) -> list[str]
getQueueEvents(self: depthai.Device, maxNumEvents: int = 18446744073709551615, timeout: datetime.timedelta = datetime.timedelta(days=-1, seconds=86399, microseconds=999999)) -> list[str]
-
getStereoPairs(self: depthai.DeviceBase) → list[depthai.StereoPair]
-
getSystemInformationLoggingRate(self: depthai.DeviceBase) → float
-
getUsbSpeed(self: depthai.DeviceBase) → depthai.UsbSpeed
-
getXLinkChunkSize(self: depthai.DeviceBase) → int
-
hasCrashDump(self: depthai.DeviceBase) → bool
-
isClosed(self: depthai.DeviceBase) → bool
-
isEepromAvailable(self: depthai.DeviceBase) → bool
-
isPipelineRunning(self: depthai.DeviceBase) → bool
-
readCalibration(self: depthai.DeviceBase) → depthai.CalibrationHandler
-
readCalibration2(self: depthai.DeviceBase) → depthai.CalibrationHandler
-
readCalibrationOrDefault(self: depthai.DeviceBase) → depthai.CalibrationHandler
-
readCalibrationRaw(self: depthai.DeviceBase) → list[int]
-
readFactoryCalibration(self: depthai.DeviceBase) → depthai.CalibrationHandler
-
readFactoryCalibrationOrDefault(self: depthai.DeviceBase) → depthai.CalibrationHandler
-
readFactoryCalibrationRaw(self: depthai.DeviceBase) → list[int]
-
removeLogCallback(self: depthai.DeviceBase, callbackId: int) → bool
-
setIrFloodLightBrightness(self: depthai.DeviceBase, mA: float, mask: int = - 1) → bool
-
setIrFloodLightIntensity(self: depthai.DeviceBase, intensity: float, mask: int = - 1) → bool
-
setIrLaserDotProjectorBrightness(self: depthai.DeviceBase, mA: float, mask: int = - 1) → bool
-
setIrLaserDotProjectorIntensity(self: depthai.DeviceBase, intensity: float, mask: int = - 1) → bool
-
setLogLevel(self: depthai.DeviceBase, level: depthai.LogLevel) → None
-
setLogOutputLevel(self: depthai.DeviceBase, level: depthai.LogLevel) → None
-
setSystemInformationLoggingRate(self: depthai.DeviceBase, rateHz: float) → None
-
setTimesync(*args, **kwargs) Overloaded function.
setTimesync(self: depthai.DeviceBase, arg0: datetime.timedelta, arg1: int, arg2: bool) -> None
setTimesync(self: depthai.DeviceBase, enable: bool) -> None
-
setXLinkChunkSize(self: depthai.DeviceBase, sizeBytes: int) → None
-
startIMUFirmwareUpdate(self: depthai.DeviceBase, forceUpdate: bool = False) → bool
-
startPipeline(*args, **kwargs) Overloaded function.
startPipeline(self: depthai.DeviceBase) -> None
startPipeline(self: depthai.DeviceBase, arg0: depthai.Pipeline) -> bool
-
-
class
dai::Device: public dai::DeviceBase¶ Represents the DepthAI device with the methods to interact with it. Implements the host-side queues to connect with XLinkIn and XLinkOut nodes
Public Functions
-
Device(const Pipeline &pipeline)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
pipeline: Pipeline to be executed on the device
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>Device(const Pipeline &pipeline, T usb2Mode)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
pipeline: Pipeline to be executed on the deviceusb2Mode: (bool) Boot device using USB2 mode firmware
-
Device(const Pipeline &pipeline, UsbSpeed maxUsbSpeed)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
pipeline: Pipeline to be executed on the devicemaxUsbSpeed: Maximum allowed USB speed
-
Device(const Pipeline &pipeline, const dai::Path &pathToCmd)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
-
Device(const Pipeline &pipeline, const DeviceInfo &devInfo)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect to
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>Device(const Pipeline &pipeline, const DeviceInfo &devInfo, T usb2Mode)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect tousb2Mode: (bool) Boot device using USB2 mode firmware
-
Device(const Pipeline &pipeline, const DeviceInfo &devInfo, UsbSpeed maxUsbSpeed)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect tomaxUsbSpeed: Maximum allowed USB speed
-
Device(const Pipeline &pipeline, const DeviceInfo &devInfo, const dai::Path &pathToCmd)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect topathToCmd: Path to custom device firmware
-
Device()¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout. Uses OpenVINO version OpenVINO::VERSION_UNIVERSAL
-
~Device() override¶ dtor to close the device
-
std::shared_ptr<DataOutputQueue>
getOutputQueue(const std::string &name)¶ Gets an output queue corresponding to stream name. If it doesn’t exist it throws
- Return
Smart pointer to DataOutputQueue
- Parameters
name: Queue/stream name, created by XLinkOut node
-
std::shared_ptr<DataOutputQueue>
getOutputQueue(const std::string &name, unsigned int maxSize, bool blocking = true)¶ Gets a queue corresponding to stream name, if it exists, otherwise it throws. Also sets queue options
- Return
Smart pointer to DataOutputQueue
- Parameters
name: Queue/stream name, set in XLinkOut nodemaxSize: Maximum number of messages in queueblocking: Queue behavior once full. True specifies blocking and false overwriting of oldest messages. Default: true
-
std::vector<std::string>
getOutputQueueNames() const¶ Get all available output queue names
- Return
Vector of output queue names
-
std::shared_ptr<DataInputQueue>
getInputQueue(const std::string &name)¶ Gets an input queue corresponding to stream name. If it doesn’t exist it throws
- Return
Smart pointer to DataInputQueue
- Parameters
name: Queue/stream name, set in XLinkIn node
-
std::shared_ptr<DataInputQueue>
getInputQueue(const std::string &name, unsigned int maxSize, bool blocking = true)¶ Gets an input queue corresponding to stream name. If it doesn’t exist it throws. Also sets queue options
- Return
Smart pointer to DataInputQueue
- Parameters
name: Queue/stream name, set in XLinkIn nodemaxSize: Maximum number of messages in queueblocking: Queue behavior once full. True: blocking, false: overwriting of oldest messages. Default: true
-
std::vector<std::string>
getInputQueueNames() const¶ Get all available input queue names
- Return
Vector of input queue names
-
std::vector<std::string>
getQueueEvents(const std::vector<std::string> &queueNames, std::size_t maxNumEvents = std::numeric_limits<std::size_t>::max(), std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶ Gets or waits until any of specified queues has received a message
- Return
Names of queues which received messages first
- Parameters
queueNames: Names of queues for which to blockmaxNumEvents: Maximum number of events to remove from queue - Default is unlimitedtimeout: Timeout after which return regardless. If negative then wait is indefinite - Default is -1
-
std::vector<std::string>
getQueueEvents(const std::initializer_list<std::string> &queueNames, std::size_t maxNumEvents = std::numeric_limits<std::size_t>::max(), std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶
-
std::vector<std::string>
getQueueEvents(std::string queueName, std::size_t maxNumEvents = std::numeric_limits<std::size_t>::max(), std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶ Gets or waits until specified queue has received a message
- Return
Names of queues which received messages first
- Parameters
queueName: Name of queues for which to wait formaxNumEvents: Maximum number of events to remove from queue. Default is unlimitedtimeout: Timeout after which return regardless. If negative then wait is indefinite. Default is -1
-
std::vector<std::string>
getQueueEvents(std::size_t maxNumEvents = std::numeric_limits<std::size_t>::max(), std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶ Gets or waits until any queue has received a message
- Return
Names of queues which received messages first
- Parameters
maxNumEvents: Maximum number of events to remove from queue. Default is unlimitedtimeout: Timeout after which return regardless. If negative then wait is indefinite. Default is -1
-
std::string
getQueueEvent(const std::vector<std::string> &queueNames, std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶ Gets or waits until any of specified queues has received a message
- Return
Queue name which received a message first
- Parameters
queueNames: Names of queues for which to wait fortimeout: Timeout after which return regardless. If negative then wait is indefinite. Default is -1
-
std::string
getQueueEvent(const std::initializer_list<std::string> &queueNames, std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶
-
std::string
getQueueEvent(std::string queueName, std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶ Gets or waits until specified queue has received a message
- Return
Queue name which received a message
- Parameters
queueNames: Name of queues for which to wait fortimeout: Timeout after which return regardless. If negative then wait is indefinite. Default is -1
-
std::string
getQueueEvent(std::chrono::microseconds timeout = std::chrono::microseconds(-1))¶ Gets or waits until any queue has received a message
- Return
Queue name which received a message
- Parameters
timeout: Timeout after which return regardless. If negative then wait is indefinite. Default is -1
-
DeviceBase(const Pipeline &pipeline)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
pipeline: Pipeline to be executed on the device
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>DeviceBase(const Pipeline &pipeline, T usb2Mode)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
pipeline: Pipeline to be executed on the deviceusb2Mode: Boot device using USB2 mode firmware
-
DeviceBase(const Pipeline &pipeline, UsbSpeed maxUsbSpeed)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
pipeline: Pipeline to be executed on the devicemaxUsbSpeed: Maximum allowed USB speed
-
DeviceBase(const Pipeline &pipeline, const dai::Path &pathToCmd)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
-
DeviceBase(const Pipeline &pipeline, const DeviceInfo &devInfo)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect to
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>DeviceBase(const Pipeline &pipeline, const DeviceInfo &devInfo, T usb2Mode)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect tousb2Mode: Boot device using USB2 mode firmware
-
DeviceBase(const Pipeline &pipeline, const DeviceInfo &devInfo, UsbSpeed maxUsbSpeed)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect tomaxUsbSpeed: Maximum allowed USB speed
-
DeviceBase(const Pipeline &pipeline, const DeviceInfo &devInfo, const dai::Path &pathToCmd)¶ Connects to device specified by devInfo.
- Parameters
pipeline: Pipeline to be executed on the devicedevInfo: DeviceInfo which specifies which device to connect topathToCmd: Path to custom device firmware
-
DeviceBase()¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout. Uses OpenVINO version OpenVINO::VERSION_UNIVERSAL
-
DeviceBase(OpenVINO::Version version)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
version: OpenVINO version which the device will be booted with.
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>DeviceBase(OpenVINO::Version version, T usb2Mode)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
version: OpenVINO version which the device will be booted withusb2Mode: Boot device using USB2 mode firmware
-
DeviceBase(OpenVINO::Version version, UsbSpeed maxUsbSpeed)¶ Connects to device specified by devInfo.
- Parameters
version: OpenVINO version which the device will be booted withmaxUsbSpeed: Maximum allowed USB speed
-
DeviceBase(OpenVINO::Version version, const dai::Path &pathToCmd)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
-
DeviceBase(OpenVINO::Version version, const DeviceInfo &devInfo)¶ Connects to device specified by devInfo.
- Parameters
version: OpenVINO version which the device will be booted withdevInfo: DeviceInfo which specifies which device to connect to
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>DeviceBase(OpenVINO::Version version, const DeviceInfo &devInfo, T usb2Mode)¶ Connects to device specified by devInfo.
- Parameters
version: OpenVINO version which the device will be booted withdevInfo: DeviceInfo which specifies which device to connect tousb2Mode: Boot device using USB2 mode firmware
-
DeviceBase(OpenVINO::Version version, const DeviceInfo &devInfo, UsbSpeed maxUsbSpeed)¶ Connects to device specified by devInfo.
- Parameters
version: OpenVINO version which the device will be booted withdevInfo: DeviceInfo which specifies which device to connect tomaxUsbSpeed: Maximum allowed USB speed
-
DeviceBase(OpenVINO::Version version, const DeviceInfo &devInfo, const dai::Path &pathToCmd)¶ Connects to device specified by devInfo.
- Parameters
version: OpenVINO version which the device will be booted withdevInfo: DeviceInfo which specifies which device to connect topathToCmd: Path to custom device firmware
-
DeviceBase(Config config)¶ Connects to any available device with custom config.
- Parameters
config: Device custom configuration to boot with
-
DeviceBase(Config config, const DeviceInfo &devInfo)¶ Connects to device ‘devInfo’ with custom config.
- Parameters
config: Device custom configuration to boot withdevInfo: DeviceInfo which specifies which device to connect to
-
DeviceBase(const DeviceInfo &devInfo)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout. Uses OpenVINO version OpenVINO::VERSION_UNIVERSAL
- Parameters
devInfo: DeviceInfo which specifies which device to connect to
-
DeviceBase(const DeviceInfo &devInfo, UsbSpeed maxUsbSpeed)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout. Uses OpenVINO version OpenVINO::VERSION_UNIVERSAL
- Parameters
devInfo: DeviceInfo which specifies which device to connect tomaxUsbSpeed: Maximum allowed USB speed
-
DeviceBase(std::string nameOrDeviceId)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout. Uses OpenVINO version OpenVINO::VERSION_UNIVERSAL
- Parameters
nameOrDeviceId: Creates DeviceInfo with nameOrDeviceId to connect to
-
DeviceBase(std::string nameOrDeviceId, UsbSpeed maxUsbSpeed)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout. Uses OpenVINO version OpenVINO::VERSION_UNIVERSAL
- Parameters
nameOrDeviceId: Creates DeviceInfo with nameOrDeviceId to connect tomaxUsbSpeed: Maximum allowed USB speed
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>DeviceBase(Config config, T usb2Mode)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
config: Config with which the device will be booted withusb2Mode: Boot device using USB2 mode firmware
-
DeviceBase(Config config, UsbSpeed maxUsbSpeed)¶ Connects to device specified by devInfo.
- Parameters
config: Config with which the device will be booted withmaxUsbSpeed: Maximum allowed USB speed
-
DeviceBase(Config config, const dai::Path &pathToCmd)¶ Connects to any available device with a DEFAULT_SEARCH_TIME timeout.
- Parameters
config: Config with which the device will be booted withpathToCmd: Path to custom device firmware
-
template<typename
T, std::enable_if_t<std::is_same<T, bool>::value, bool> = true>DeviceBase(Config config, const DeviceInfo &devInfo, T usb2Mode)¶ Connects to device specified by devInfo.
- Parameters
config: Config with which the device will be booted withdevInfo: DeviceInfo which specifies which device to connect tousb2Mode: Boot device using USB2 mode firmware
-
DeviceBase(Config config, const DeviceInfo &devInfo, UsbSpeed maxUsbSpeed)¶ Connects to device specified by devInfo.
- Parameters
config: Config with which the device will be booted withdevInfo: DeviceInfo which specifies which device to connect tomaxUsbSpeed: Maximum allowed USB speed
-
DeviceBase(Config config, const DeviceInfo &devInfo, const dai::Path &pathToCmd, bool dumpOnly = false)¶ Connects to device specified by devInfo.
- Parameters
config: Config with which the device will be booted withdevInfo: DeviceInfo which specifies which device to connect topathToCmd: Path to custom device firmwaredumpOnly: If true only the minimal connection is established to retrieve the crash dump
Public Static Attributes
-
constexpr std::size_t
EVENT_QUEUE_MAXIMUM_SIZE= {2048}¶ Maximum number of elements in event queue.
Private Functions
-
bool
startPipelineImpl(const Pipeline &pipeline) override¶ Allows the derived classes to handle custom setup for starting the pipeline
- See
- Note
Remember to call this function in the overload to setup the communication properly
- Return
True if pipeline started, false otherwise
- Parameters
pipeline: OpenVINO version of the pipeline must match the one which the device was booted with
-
void
closeImpl() override¶ Allows the derived classes to handle custom setup for gracefully stopping the pipeline
- Note
Remember to call this function in the overload to setup the communication properly
Private Members
-
std::unordered_map<std::string, std::shared_ptr<DataOutputQueue>>
outputQueueMap¶
-
std::unordered_map<std::string, std::shared_ptr<DataInputQueue>>
inputQueueMap¶
-
std::unordered_map<std::string, DataOutputQueue::CallbackId>
callbackIdMap¶
-
std::mutex
eventMtx¶
-
std::condition_variable
eventCv¶
-
std::deque<std::string>
eventQueue¶
-